
Client Story
A UK-based automotive parts distributor was building an AI system to automate parts ordering for repair workshops. To train their predictive ordering models, they didn’t just need data — they needed a high-frequency, multi-source data pipeline.
| Industry: | Automotive |
|---|---|
| Location: | United Kingdom / EU |
| Year: | 2026 |
Read summarized version with
"I think initially, we want to collect as much data as possible. That builds the foundations of our parts catalog. And then on an ongoing basis — when a vehicle comes into a workshop, we want to try and find that vehicle from one or two websites." — Co-founder, UK Auto Parts Startup
"This source specifically is an awful lot of data there, and we would like Nissan as quickly as possible. We'd prioritise the brands, because once that data access reaches the team, they can process that and turn it into the product that we're doing." — Director, UK Auto Parts Startup
Beyond Static Datasets
The client’s AI system scours distributor catalogs to find exact components for specific vehicle makes, models, and years. They faced three critical roadblocks:
- Rigid Vendors: Existing data providers offered generic datasets that lacked niche distributor sources like Parts Bond.
- Authentication Barriers: Parts Bond’s login-protected environment and complex registration prevented standard scraping tools from accessing real-time pricing and stock.
- Scalability Debt: Every new distributor source meant starting from scratch. The architecture had to support growth, not become a bottleneck to it.
A Modular "Pluggable" Architecture
Instead of a one-off script, GroupBWT built a Multi-Source Scraping Engine. This architecture separates the core logic (proxy management, rotation, storage) from site-specific rules.
- Automated Identity Management
To crack the Parts Bond barrier, we automated white-hat account creation. Using dedicated corporate inboxes and automated verification handling, the system generates and manages access credentials without manual intervention.
- The “Plug-in” Scaling Model
Each new distributor (e.g., Arnold Clark, Parts 2 World) is treated as a separate module.- Core Engine: Handles proxy rotation, anti-bot bypass, and data validation.
- Site Modules: Parsers for specific UI layouts.
- Result: Adding a new source now takes days, not weeks.
- ML-Ready Data Delivery
Data is delivered in structured JSON, mapping OE numbers, compatibility matrices, and live pricing directly into the client’s database.
Tech Stack: Python 3.12, Scrapy, RabbitMQ, MySQL, K8s/Helm/ArgoCD, Custom Proxy Rotation.
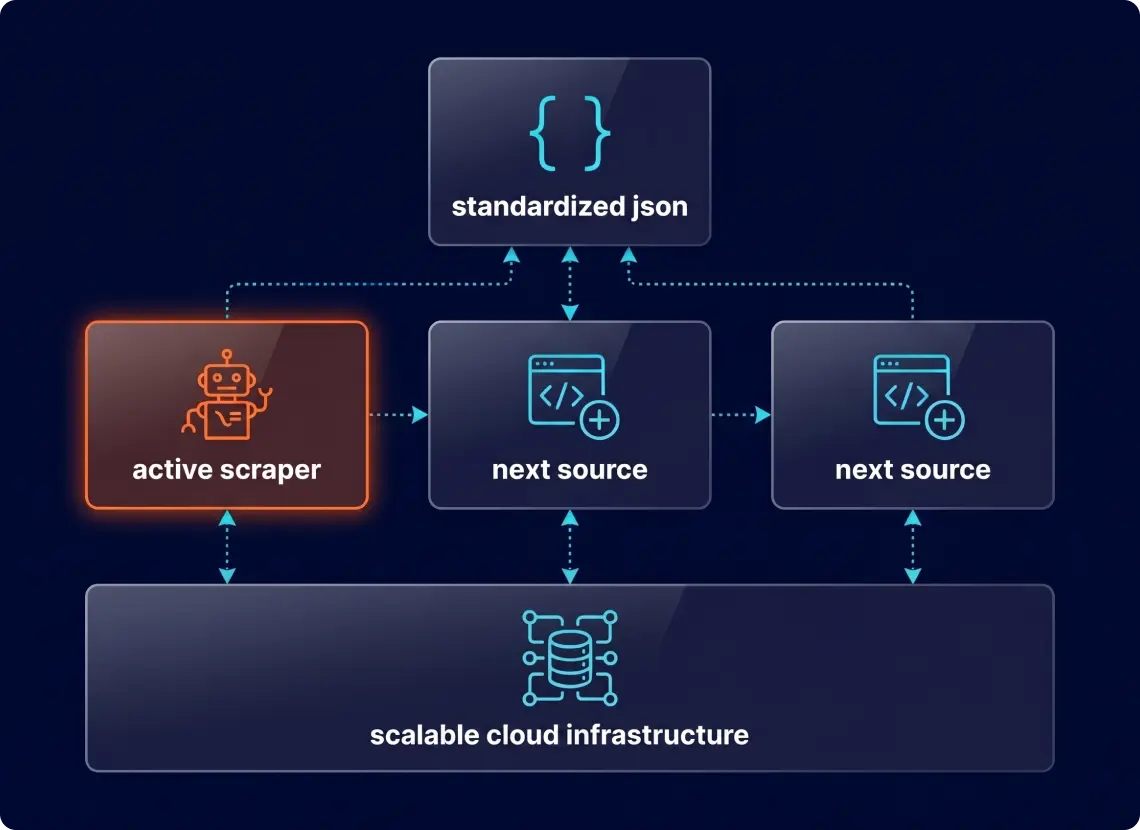
Building a one-off scraper for a single source is the wrong answer when the client has 20 more sites in plans. We scoped this as a multi-source platform from day one — so each new distributor becomes a module added to something already running, not another ground-up project.

From Zero to 6.3M Records
Speed was the primary metric, and we delivered: the first major Nissan dataset was in the client’s hands in just three weeks. This wasn’t a shallow sample; we extracted 6.3M+ part records, 270 GB of structured catalog data. Most importantly, the architecture supports additional distributor sources without a rebuild.
Roadmap: Phase 2 (Real-Time API)
With the initial dataset delivered, we are moving toward a Real-Time API Endpoint. When a car enters a repair bay, the system will ping the source instantly, providing pricing and availability.

Looking for a Scalable Data Partner?
If your AI product depends on high-quality, high-volume automotive data, don't settle for static datasets. Build a machine that grows with your business.




You have an idea?
We handle all the rest.
How can we help you?
