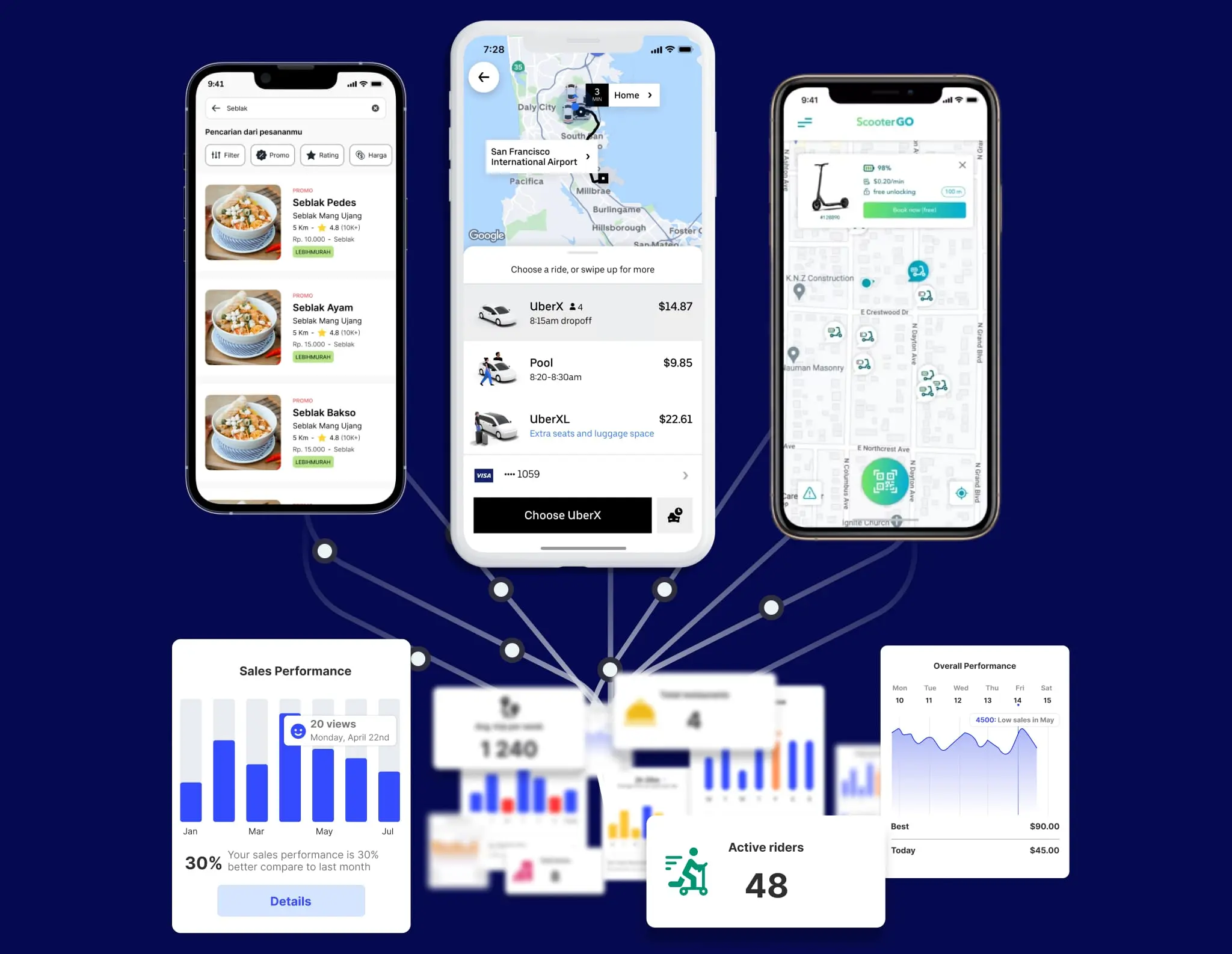
See what we have built
for our clients
/02
Software for
Software for
Software for
Software for
Software for
Software for
Software for
Software for
Software for

How we apply our
expertise
We combine our 15 years of experience in custom software development with top-notch expertise in data science and digital product design to craft world-class data aggregation software.
Data Science
01.Data mining, Data Analysis, Machine Learning, Natural Language Processing.

Data
Science
-
01
Custom Software Development
02.Tailored digital solutions from scratch for your business needs.

Custom Software
Development
-
02
Digital Product Design
03.Smart and beautiful Web and Mobile UI/UX design that users will love.

Digital Product
Design
-
03







Ready to begin building your custom web scraping solution?
Talk to us:
Write to us:
Solutions
Our knowledge and experience, packaged into solutions addressing the most popular challenges

Data
Aggregator
We develop a multi-source data scraping platform exclusively owned by you

Insights
Radar
We develop custom software to extract insights from publicly available data exclusively for you.
Compliance
Leaders in
Data Security
We’ve set the gold standard for ethical web data practices, ensuring compliance and trust. With a commitment to zero personal data collection, your privacy and security are our top priorities.
GDPR
Compliant
ISO 27001
Certified
HIPAA
Compliant
Our partnerships and awards
")
")








We extract structured data from complex, geo-restricted sources—eCommerce platforms, mobile apps, marketplaces, real estate directories, and review or comparison sites. Each system is built for adaptability. We replicate actual user behavior across regions using rotating residential and mobile proxies. IP bans, CAPTCHAs, or dynamic JavaScript are anticipated. If a proxy fails, we reroute. If access rules change, we adapt. Resilience is engineered from the start, not patched later.
Yes. We can match your data schema or create a structured format aligned to your objectives. Every column, header, and data type is defined before launch, so nothing is left to assumption.
Once the scope is confirmed, delivery begins immediately. The launch pipeline includes technical discovery, scraper engineering with QA, a proof-of-concept in a test region, and full deployment. Results start appearing within days. Our systems scale from 10,000 to over 900,000 daily requests, rolled out in phases to ensure reliability and compliance.
The proof-of-concept includes 10K–100K targeted requests in a defined region or category, executed over several days. It delivers clean datasets, QA logs, and diagnostics, validating technical readiness and business value before scaling.
We follow a stepwise model. The pilot runs at 10K–100K daily requests for tuning. Next, the infrastructure scales to 300K per day. We then trial 900K+ per day under high load for one to two months. Long-term operations stabilize around 300K per day, balancing throughput and system integrity.
Rarely—and never without a fallback. Scraping traffic is spread across a proxy mesh designed to mimic real users. No IP, region, or fingerprint is overloaded. The load is ramped gradually. If a provider blocks traffic, we reroute instantly.
We build data pipelines—not just scrapers. During onboarding, we assess your stack (databases, APIs, BI tools) and configure delivery through ETL/ELT workflows, data lake ingestion, direct DB writes, or API syncs. Every integration is secure, efficient, and tailored.
Costs depend on source complexity, update frequency, request volume, anti-bot defenses (e.g., CAPTCHA, headless JS), and output format (JSON, CSV, API, or DB). We design for scale and longevity—short-term fixes aren’t our approach. Large, recurring operations see meaningful cost efficiency.
Support is entirely in-house. You receive technical documentation (source maps, schemas, workflows), a dedicated engineering team, and a clear SLA for issue response and continuity. We remain engaged after go-live, stabilizing and optimizing your system as it evolves.
Because real-time scraping needs real-time car, post-launch systems must adjust to frontend/API changes, rebalance loads, and evolve with business needs across teams. Part-time support may be possible later, but for the first 90–180 days, full-time attention prevents instability and data loss.
Still have any questions? Contact us

You have an idea?
We handle all the rest.
How can we help you?