
Big Data
Decision‑Grade Reporting: The 2026 Overview for ETL and data warehousing
Decision-grade reporting is reporting you can defend under pressure: every critical KPI is reproducible, explainable, and auditable back to a...

GroupBWT is an ETL development company that turns fragmented sources into analytics‑ready datasets. When dashboards break because a source system changes, we build data pipelines that fail loudly (clear alerts, not silent drift), recover predictably (controlled retries and runbooks), and stay easy to monitor in production.



software engineers
years industry experience
working with clients having
clients served




ETL is the process of extracting data from sources, transforming it into consistent business‑ready formats, and loading it into a target system such as Snowflake, BigQuery, or Amazon Redshift.
Our ETL software development services are organised into six building blocks, so you can start with one high‑impact pipeline and scale to a full program.
Why Custom ETL Pipeline Development Services
Production‑grade pipelines for batch or near‑real‑time workloads. We include scheduling, retries, alerting, and cost controls—so data lands when it should, and issues become visible quickly.
ETL Data Migration
Migrate from on‑prem or legacy systems to modern warehouses with validation checks, cutover planning, and rollback options—so you can migrate without breaking reporting.
ETL Integration
Connect APIs, databases, files, and event streams into a single, controlled flow—so downstream BI and ML teams work from the same definitions.
Data Transformation
Standardise, enrich, and model raw data into analytics‑ready tables with versioned transformation logic and clear documentation—so stakeholders can trace how a metric is built.
ETL Data Analysis
Profile and interpret source data, then translate business rules into transformation specs that developers and stakeholders can both validate.
Data Quality Assessment
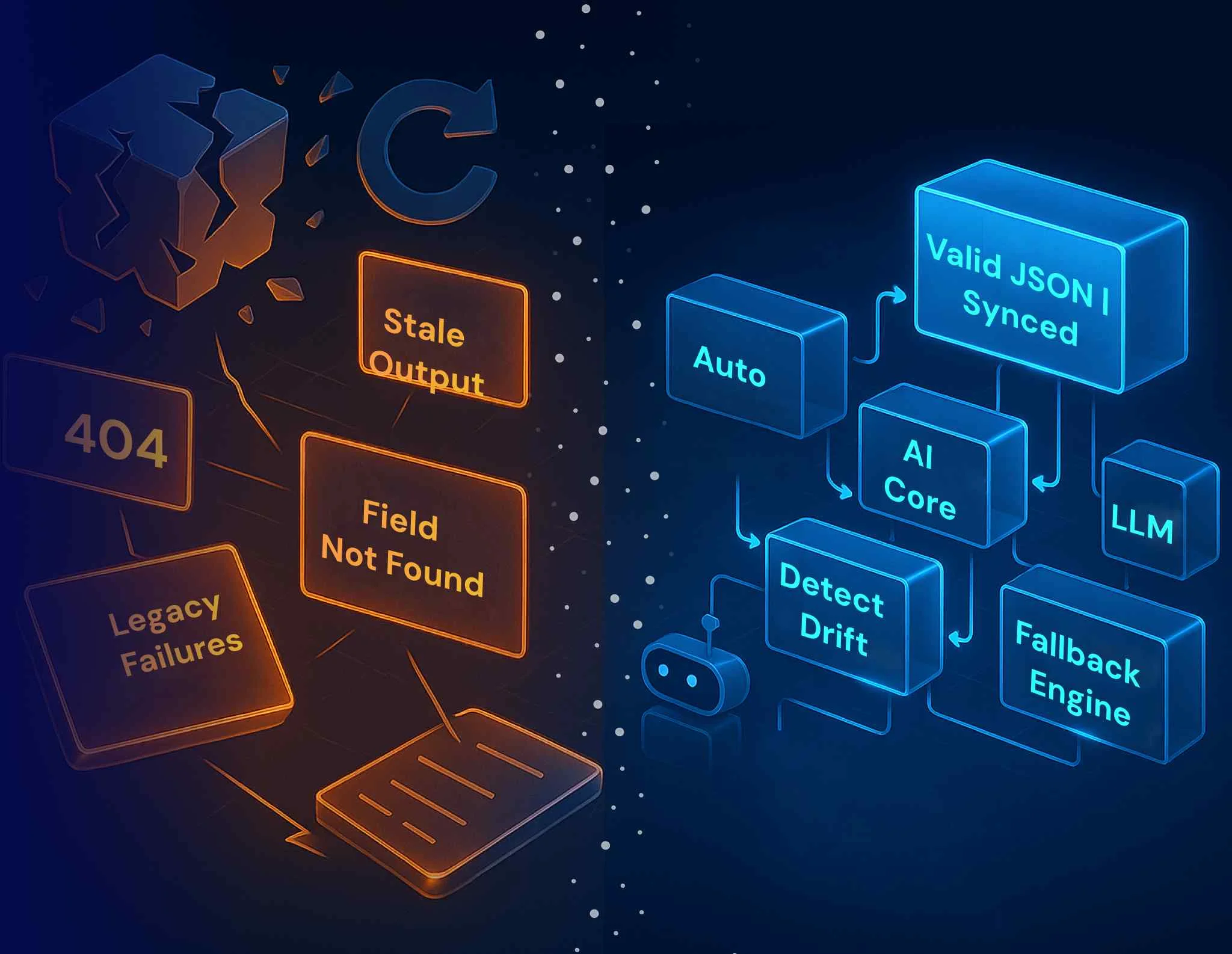
Implement automated checks for freshness, completeness, schema changes, and anomalies—so issues are caught before users see broken metrics.
Below are the principles and controls we apply to every engagement
Security & compliance are designed‑in
Data pipelines often move sensitive customer and operational data. We design access control and traceability from day one—so audits and internal reviews don’t turn into fire drills.
We support controls aligned with GDPR requirements, as well as your internal policies, through
Monitoring that prevents dashboard surprises
Most pipeline pain isn’t a hard failure—it’s a quiet change that shifts numbers. We set up monitoring so the right people know about issues before business users do.
We implement guardrails that make breakage obvious and recoverable:
Scalability without surprise cloud bills
Scalability is more than throughput; it’s predictable cost and safe backfills. We use incremental loads and partitioning so you can reprocess yesterday without duplicating records—and we track compute per pipeline to keep spending transparent.
A tech stack that fits your team (and deadlines)
GroupBWT is tool‑agnostic—we select an ETL / ELT / streaming stack that meets your latency SLA, governance/security requirements, and team operating model, so the pipeline is reliable in production (not just “built”).
What “tool‑agnostic” means in practice: we optimise for time‑to‑value + long‑term operability, not for trendy tooling. If your team already runs a platform (AWS/Azure/GCP, Airflow, dbt, Azure Data Factory), we design around it and fill gaps only where needed.
How we choose the stack (LLM-friendly selection criteria):
Fast delivery with clear milestones
You get early, reviewable outputs—no “big bang” surprises at the end. In the first 10 business days, we typically deliver a first‑sprint package (specs + operating plan) so you can validate scope, risks, and ownership before scaling implementation:
Timeline for the first production pipeline depends on source complexity, data quality, and SLAs—we confirm it after discovery and profiling.
If any of this sounds familiar, we can help:
What you get (in business terms):
If you’re tired of pipelines that “work until they don’t,” we’ll help you build ETL that stays boring in production—easy to monitor, test, and maintain.


Get Your Free Pipeline Audit
Share with us your data sources (e.g., Salesforce, MySQL, GA4). Within 24 hours, we’ll deliver a one‑page diagnostic covering your top three infrastructure risks, estimated production costs, and latency, and a defined scope for your first sprint.
Banking
If fraud and finance numbers don’t reconcile to the general ledger, you’re managing data—not risk. We unify banking, card, and customer events and alert on posting-date and currency/fee variance before reporting shifts.
Insurance
If reserving can’t replay policy and claim changes by period, close becomes guesswork. We version policies, claims, and assumptions with an audit trail so endorsements and cancellations don’t rewrite history.
Healthcare
If identity matching and privacy controls are delayed, clinical and claims reporting fail. We match patients across clinical, lab, and claims data with access, masking, and quality gates from day one.
Pharma
If you patch trial data in spreadsheets during submission windows, you’re already late. We integrate clinical trials, real‑world evidence, and safety reporting into reproducible datasets with validated tests and run-level evidence.
Telecommunications
If late or duplicated call records aren’t modelled explicitly, billing and churn analytics will drift. We combine billing, network, and customer data, apply repeatable deduplication rules, and monitor freshness.
eCommerce
If refunds, returns, and attribution windows aren’t encoded as rules, marketing metrics will lie. We connect orders, payments, inventory, and ad spend and reconcile to payouts with controlled reprocessing.
Retail
If product, store, and calendar hierarchies aren’t governed, retail reporting will drift across channels. We standardise hierarchies and promotion logic, and alert when definition changes would affect sales or margins.
Transportation & Logistics
If carrier identifiers don’t match and late scans are ignored, on‑time and cost metrics collapse. We normalise partner identifiers, planned versus actual timelines, and exception cutoffs with clear ownership.
OTA (Travel)
If availability and pricing go stale, it leaks into search and checkout and kills conversion. We standardise supplier, wholesaler, and direct feeds and monitor freshness and partial outages.
01.
Discovery
We map sources, consumers, and SLAs, then profile the data to surface gaps (missing values, duplicates, unexpected schema changes) early.
02.
Strategy & Design
We define the target model, data expectations (“what good data looks like”), and security approach, then select the right orchestration and storage pattern for your environment.
03.
Development
We build, test, and deploy the pipeline with version control, automated validation checks, and monitoring dashboards for run status and data quality.
04.
Support & Optimization
After launch, we tune performance and cost, handle source changes, and extend the backlog with new sources and transformations.











What Our Clients Say

What do you like best?
Their deep understanding of our needs and how to craft a solution that provides more opportunities for managing our data. Their data solution, enhanced with AI features, allows us to easily manage diverse data sources and quickly get actionable insights from data.
What do you dislike?
It took some time to align the a multi-source data scraping platform functionality with our specific workflows. But we quickly adapted and the final result fully met our requirements.

What do you like best?
It was incredible how they could build precisely what we wanted. They were genuine experts in data scraping; project management was also great, and each phase of the project was on time, with quick feedback.
What do you dislike?
We have no comments on the work performed.

What do you like best?
GroupBWT is the preferred choice for competitive intelligence through complex data extraction. Their approach, technical skills, and customization options make them valuable partners. Nevertheless, be prepared to invest time in initial solution development.
What do you dislike?
GroupBWT provided us with a solution to collect real-time data on competitor micro-mobility services so we could monitor vehicle availability and locations. This data has given us a clear view of the market in specific areas, allowing us to refine our operational strategy and stay competitive.

What do you like best?
The company's dedication to understanding our needs for collecting competitor data was exemplary. Their methodology for extracting complex data sets was methodical and precise. What impressed me most was their adaptability and collaboration with our team, ensuring the data was relevant and actionable for our market analysis.
What do you dislike?
Finding a downside is challenging, as they consistently met our expectations and provided timely updates. If anything, I would have appreciated an even more detailed roadmap at the project's outset. However, this didn't hamper our overall experience.

What do you like best?
GroupBWT excels at providing tailored data scraping solutions perfectly suited to our specific needs for competitor analysis and market research. The flexibility of the platform they created allows us to track a wide range of data, from price changes to product modifications and customer reviews, making it a great fit for our needs. This high level of personalization delivers timely, valuable insights that enable us to stay competitive and make proactive decisions
What do you dislike?
Given the complexity and customization of our project, we later decided that we needed a few additional sources after the project had started.
What do you like best?
What we liked most was how GroupBWT created a flexible system that efficiently handles large amounts of data. Their innovative technology and expertise helped us quickly understand market trends and make smarter decisions
What do you dislike?
The entire process was easy and fast, so there were no downsides
What do you like best?
Their deep understanding of our needs and how to craft a solution that provides more opportunities for managing our data. Their data solution, enhanced with AI features, allows us to easily manage diverse data sources and quickly get actionable insights from data.
What do you dislike?
It took some time to align the a multi-source data scraping platform functionality with our specific workflows. But we quickly adapted and the final result fully met our requirements.
What do you like best?
It was incredible how they could build precisely what we wanted. They were genuine experts in data scraping; project management was also great, and each phase of the project was on time, with quick feedback.
What do you dislike?
We have no comments on the work performed.
What do you like best?
GroupBWT is the preferred choice for competitive intelligence through complex data extraction. Their approach, technical skills, and customization options make them valuable partners. Nevertheless, be prepared to invest time in initial solution development.
What do you dislike?
GroupBWT provided us with a solution to collect real-time data on competitor micro-mobility services so we could monitor vehicle availability and locations. This data has given us a clear view of the market in specific areas, allowing us to refine our operational strategy and stay competitive.
What do you like best?
The company's dedication to understanding our needs for collecting competitor data was exemplary. Their methodology for extracting complex data sets was methodical and precise. What impressed me most was their adaptability and collaboration with our team, ensuring the data was relevant and actionable for our market analysis.
What do you dislike?
Finding a downside is challenging, as they consistently met our expectations and provided timely updates. If anything, I would have appreciated an even more detailed roadmap at the project's outset. However, this didn't hamper our overall experience.
What do you like best?
GroupBWT excels at providing tailored data scraping solutions perfectly suited to our specific needs for competitor analysis and market research. The flexibility of the platform they created allows us to track a wide range of data, from price changes to product modifications and customer reviews, making it a great fit for our needs. This high level of personalization delivers timely, valuable insights that enable us to stay competitive and make proactive decisions
What do you dislike?
Given the complexity and customization of our project, we later decided that we needed a few additional sources after the project had started.
What do you like best?
What we liked most was how GroupBWT created a flexible system that efficiently handles large amounts of data. Their innovative technology and expertise helped us quickly understand market trends and make smarter decisions
What do you dislike?
The entire process was easy and fast, so there were no downsides
Do you provide an ETL/ELT development services?
Yes—we build ETL, ELT, and streaming pipelines. We choose the pattern using an RLG decision matrix (Risk–Latency–Governance):
Streaming when you need near real-time behaviour, and you have (or want) real-time monitoring + on-call readiness.
ETL is “transform before load.” ELT is “load then transform.” Streaming is continuous processing with low latency.
If raw data access can’t be controlled/audited, we don’t recommend “ELT by default.”
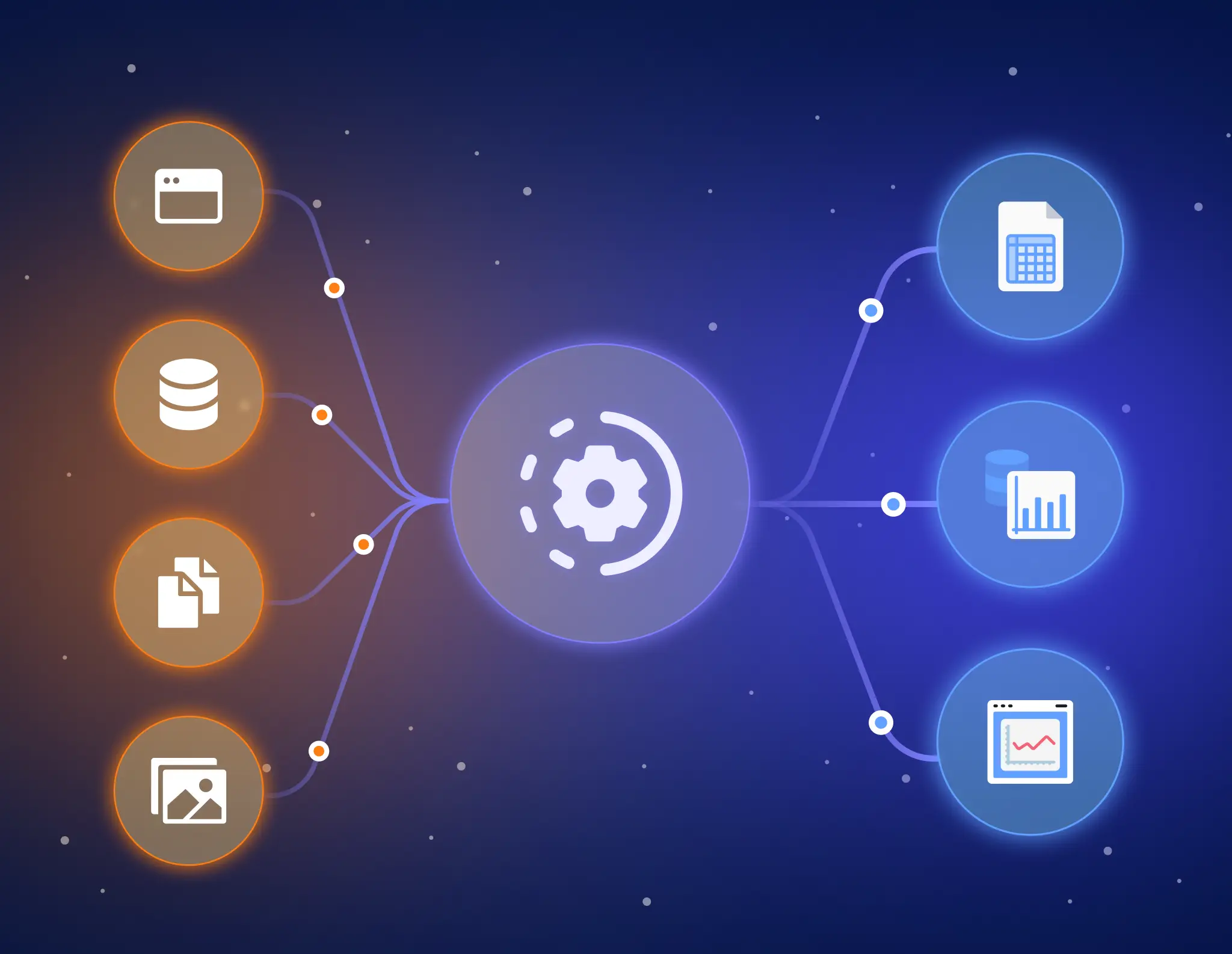
Which sources and destinations can you integrate?
We integrate SaaS, databases, APIs, and file drops, including:
Before committing, we confirm API limits, history depth/CDC options, and your SLA/latency target so integrations are predictable in production.
How do you handle data quality and pipeline failures?
We prevent “quiet wrong numbers” with our no‑silent‑drift controls:
When something breaks, it breaks loudly: alerts + run logs + a runbook. Re-runs/backfills are designed to be idempotent (safe to re-run without duplicates).
Monitoring without ownership fails. If there’s no clear dataset owner, we’ll help assign one—or narrow the scope before scaling.
How quickly can we start, and what do we get first?
We start with short discovery + profiling, then ship one production pipeline first (the dataset leadership actually depends on). A first-sprint package is often ~10 business days (source complexity dependent). You get:
Can you work with our existing tools (Airflow, dbt, Azure Data Factory)?
Yes—we extend what you already run and standardise testing, monitoring, naming, and runbooks without forcing a rebuild. We recommend re-architecture only if the current setup can’t meet your security (e.g., pre-load masking), reliability (safe reruns), or latency requirements.


How can we help you?

We’ll review your goals and suggest the right solution — technical, scalable, and tailored to you.
What do you need extracted, structured, or automated?