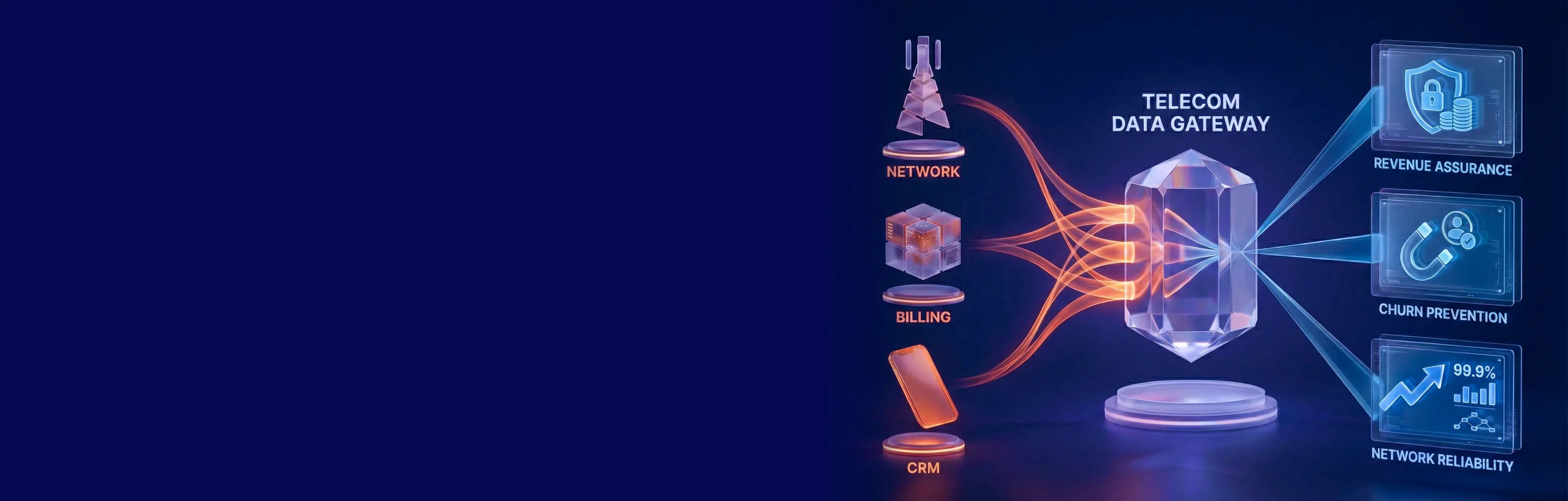

Data extraction for telecom is the disciplined process of collecting network, customer, and billing data, standardising it, and making it usable for analytics, automation, and reporting—without breaking privacy or production systems.
The latest 2026 Technology, Media & Telecommunications Predictions from Deloitte says the party is over and the real work has begun. By 2026, the simple act of inference—which is just the techie way of saying “the day-to-day running of these models”—will likely gobble up two-thirds of all AI compute. That is an insane amount of processing power. And because we’re still leaning on those beastly, power-sucking AI chips worth north of $200 billion, we’re seeing this massive gravitational pull back toward centralized data centers instead of the nimble edge-chips everyone was rooting for.
Deloitte thinks the agentic AI market could balloon to $45 billion by 2030. Can we actually handle that? Perhaps. But it only works if companies stop treating orchestration as an afterthought and actually manage these tangled, high-volume networks with some precision. Without that, all this expensive hardware is just a very pricey paperweight.
This guide is written for teams that need outcomes (QoS, churn, revenue assurance) and a repeatable delivery plan. You’ll get:
- A clear starting workflow (KPIs → sources → architecture → scale)
- A practical architecture pattern for OSS/BSS, CDRs, NDRs, and billing documents
- Common failure modes (and how to avoid them)
- Concrete examples, tables, and a starter checklist
Delivery note: GroupBWT helps operators and telecom data providers implement data extraction telecom programs that balance correlation accuracy, reliability, and privacy controls.
Glossary (so non‑engineers don’t get stuck)
This glossary explains the terms that usually slow down stakeholder alignment in data extraction for telecom projects.
- OSS/BSS are telecom support systems: OSS runs the network, BSS runs products, billing, and customers
- CDR/xDR are usage records (Call Detail Records / “extended” Detail Records) produced by network/charging systems
- NDR (Network Data Record) is a broad term for network activity and telemetry. Unlike standardized CDRs, ‘NDR’ definitions vary by operator and may refer to probe outputs, vendor-specific telemetry, or internal enriched records used for troubleshooting.
- IMSI / MSISDN / IMEI are common identifiers: IMSI = SIM identity, MSISDN = phone number, IMEI = device identity
- TAP files are roaming billing exchange files between operators (Transferred Account Procedure)
- CDC (Change Data Capture) captures incremental database changes; use it when you need near‑real‑time updates
- ETL is extract–transform–load; in telecom, you also need correlation, ID mapping, and reconciliation
- ASN.1 is a standard schema language used to define data structures (abstract syntax), which are then serialized using specific encoding rules (like BER, PER, or DER) common in telecom; Parquet is a columnar analytics file format.
- Pseudonymisation / tokenisation protects identifiers: pseudonymisation typically keeps reversibility under strict controls; tokenisation replaces identifiers with tokens plus a secure mapping
Structured, semi‑structured, and unstructured telecom data require different extraction stacks

Your extraction approach should follow the data format, not the system name. In telecom, one process (for example, “bill the customer correctly”) can touch relational tables, streaming events, and scanned PDFs.
- Structured data is data that already fits a known schema (rows/columns), such as billing tables or dimension tables in a data warehouse
- Semi‑structured data is data with flexible schemas (JSON, XML, key‑value logs), common in event streams and modern network telemetry
- Unstructured data is data that doesn’t come with a reliable schema (PDF invoices, images, email threads, call recordings), where OCR, document AI, and speech‑to‑text are used
Practical implication: data extraction for telecommunications often requires two stacks:
- Connectors + streaming/ETL for structured and semi‑structured sources
- Document processing for invoices, contracts, partner reports, and regulatory forms
Case study: turning a corporate PDF bill into audited line items
A corporate customer’s bill arrives as a PDF with separate tables for usage, roaming, taxes, and one‑time fees. Finance flags that the invoice total “looks off,” but nobody can prove why without manual checks.
A reliable approach looks like this:
- Parse the PDF and detect layout (table boundaries and headers)
- Extract line items and normalise units (currency, bytes/minutes, time zones)
- Apply validation rules (totals match, VAT rules, duplicate invoice numbers)
- Store both the extracted fields and the evidence (page/row references) for auditability
In practice, this prevents a common failure mode: the PDF “parses,” but the totals don’t reconcile, so trust collapses and teams revert to spreadsheets.
Operational, network, and customer data must be correlated to be actionable
Telecom analytics works only when you correlate “network reality” with “customer reality.” A dropped‑call metric is not actionable if you can’t map it to impacted subscribers, plans, and locations.
Here’s a practical grouping by decision type:
- Operational data (process health): tickets, field service jobs, order fallouts, provisioning logs
– Question: “Are we delivering service correctly?” - Network data (service reality): performance counters (health metrics), alarms (fault notifications), traces, CDRs/NDRs, cell KPIs
– Question: “Is the network performing as promised?” - Customer & commercial data (business impact): CRM, billing, payments, product catalog, churn labels
– Question: “Who is affected, what is it worth, and what do we do next?”
A KPI → sources → architecture → scale workflow keeps data extraction telecom initiatives focused
Start with one decision and one KPI. If you don’t, your “platform” becomes a data swamp.

Define one KPI that forces cross‑domain correlation
Pick a KPI that requires network + customer + billing to agree:
- Time to detect and localise incidents (MTTD/MTTR)
- Complaint rate per 10k subscribers by region and device
- Revenue leakage rate (estimated vs billed vs collected)
- Churn risk for high‑value segments after network events
“If your KPI can’t be computed from a single, documented gold table, you don’t have an operational KPI yet—you have a definition dispute. Build the gold table first, then build dashboards.”
— GroupBWT delivery principle
Select sources by impact and accessibility (and explain the tech choices)
Start with sources that directly support a decision:
- CDRs/NDRs for usage and service quality signals
- Trouble tickets + call‑centre tags for customer pain signals
- Billing/invoicing outputs for revenue assurance signals
Technology choices depend on latency and volume:
- Batch ingestion (daily/hourly): object storage + Spark/SQL
- Streaming ingestion (seconds/minutes): Kafka or equivalent event transport + Flink or Spark Structured Streaming (processing)
- Document extraction: OCR + table recognition + validation rules
Use data extraction telecommunications methods that include validation, not just parsing. Parsing creates fields; validation creates trust.
Your POC is ready when it survives bad data and reconciliation
A POC is done when it survives bad data—not when it works on a clean sample. Use this POC‑to‑scale gate:
- Week 1–2: Define the data contract + sample set
– Define a canonical schema (subscriber_id, cell_id, event_time_utc, charge_amount)
– Identify privacy constraints and retention rules early - Week 3–4: Build the gold dataset
– Ingest → normalise → deduplicate → quality checks
– Deliver one dashboard or API that answers one decision question - Week 5–6: Prove reliability
– Backfill a month+ of data
– Run reconciliation checks (totals, counts, uniqueness)
– Document lineage and failure handling
ROI estimation worksheet (replace with your internal numbers):
- Recovered leakage = (identified underbilling + rating gaps) × expected recovery %
- Fraud prevention = prevented fraudulent usage × gross margin
- Churn reduction = (Identified at-risk subscribers) × (Retention success rate %) × ARPU × margin
- OPEX reduction = hours saved in reporting/reconciliation × cost per hour
5–15% “at‑risk revenue” is a practical starting range for why extraction matters (then validate it)
Telecom operators often discover that a meaningful slice of revenue becomes “at risk” when usage events, rating outputs, invoices, and collections don’t reconcile. A practical modelling range many RA teams use in early discovery is 5–15%, then they replace it with real reconciled baselines.
Data extraction for telecom closes these gaps by correlating network events with billing records and settlement files fast enough to act, not just report.
Network performance monitoring works when you connect alarms, counters, and subscriber impact
You can’t optimise what you can’t measure consistently. Extraction enables:
- Near real‑time anomaly detection by cell, region, and service
- Capacity planning with historical utilisation trends
- Root‑cause workflows that join alarms + counters + subscriber impact
But network performance is only half the story. What happens to the customer next is where churn is decided.
Customer experience improves when you map sequences, not single events
Churn often follows a sequence, not a single outage. Correlation makes patterns visible:
- Congestion → retries → ticket → repeated billing dispute → churn
- Device model + location + roaming profile → repeated failures
Revenue assurance improves when you reconcile three timestamps
Revenue leakage and fraud hide in mismatches:
- Usage events exist, but rating didn’t happen
- Rating happened, but invoicing missed items
- Invoices went out, but the collections data doesn’t reconcile

“Fraud teams don’t need more AI. They need fewer blind spots. The fastest wins come from correlating three timestamps—network event time, rating time, and invoice time—and flagging drift.”
— Oleg Boyko, COO, GroupBWT
Key data sources for data extraction for telecom should follow correlation keys, not org charts
Build your source inventory around correlation keys (time, subscriber, device, location). This is where data extraction telecom becomes both engineering and governance.
Network data: CDRs, NDRs, and OSS/BSS telemetry
Common network‑side sources:
- CDRs/xDRs (voice, SMS, data sessions)
- NDRs (Network Data Records), probes, and telemetry streams
- OSS performance counters, alarms, configuration snapshots (metrics, faults, saved settings)
- Mediation outputs and network element logs
Typical pitfalls:
- Time zone inconsistencies between elements
- Missing identifier mappings (IMSI ↔ MSISDN ↔ IMEI gaps)
- Duplicate events during retries or failovers
Customer and billing data: revenue truth lives here
Business‑side sources:
- CRM and customer master data
- Product catalog and pricing/rating plans
- Billing (invoices, adjustments, discounts)
- Payments/collections and dunning status
A “gold invoice” table should include:
- invoice_id, account_id, billing_period_start/end
- line_item_type (usage/recurring/one‑time/tax)
- service_identifier (MSISDN / SIM / circuit)
- charge_amount, currency, tax_amount
External sources: roaming, IoT, partners, and open data
External sources add context and obligations:
- Roaming TAP files (Transferred Account Procedure) and partner settlements
- IoT platform event feeds
- Partner usage reports and reseller statements
- Public data for regional analysis (coverage obligations, demographics)
If you also need competitive and market context beyond internal systems, consider telecom web scraping as a complementary stream.
Table: Data source → extraction approach → quality checks
| Source | Typical format | Extraction method | Must-have quality checks |
| CDR/xDR | CSV / ASN.1 / Parquet | Batch ingestion + schema validation | Duplicates, missing IDs, event-time drift |
| OSS counters/alarms | JSON / XML / streams | Streaming ingestion + windowing | Late events, out-of-order data |
| Billing tables | SQL | SQL extract (batch) + incremental loads (CDC essential for late adjustments) | Reconcile to invoice totals, adjustments, and write-offs |
| PDF bills/partner reports | PDF / image | OCR + table detection + validation rules | Totals match, currency/unit consistency, evidence links |
| Roaming/settlement files | TAP (ASN.1) / CSV | Secure file ingestion + schema validation | Completeness per period, checksums, duplicates |
A practical telecom architecture is Ingest → Normalise → Correlate → Serve
 | GroupBWT")
The winning architecture makes correlation cheap and governance unavoidable.
“Correlation Keys First” flow
Ingest lanes (stream/batch/doc) → Normalise (IDs/time/units) → Correlate (subscriber timeline, bill integrity) → Serve (BI/API/data products)
Most teams run extraction in three lanes (and each lane has a definition of “done”)
- Streaming lane for alarms/telemetry where latency matters
- Batch lane for CDRs, billing extracts, and backfills
- Document lane for PDFs and partner files
Many data extraction telecom projects fail here: teams ingest everything, but they never define “done” for a dataset (coverage, reconciliation, ownership).
Normalisation produces canonical fields; correlation produces decision-ready entities
Normalisation should produce canonical fields:
- Unified timestamps (UTC) and unified identifiers
- Standard units (bytes, seconds, currency)
- Reference mappings (cell → site → region; IMSI ↔ MSISDN)
Correlation then joins events into decision‑ready entities:
- Subscriber experience timeline
- Incident impact set (who, where, how many)
- Bill integrity checks (what was used vs billed)
Real-time is optional; correctness is not
Use this rule:
- If the decision window is minutes (outages, fraud spikes) → streaming
- If the decision window is days/weeks (churn, planning, compliance) → batch
Challenges of data extraction in telecom are predictable (and mostly about reconciliation)
The hard part isn’t extraction—it’s reconciliation under scale and legacy constraints.
High volume, velocity, and variety push your quality layer, not just compute
- Millions of events per hour
- Bursty traffic during incidents
- Many schemas across vendors and network generations
- Mitigation: partition by time + key identifiers, tier storage (hot/warm/cold), enforce schema evolution rules
Legacy systems and silos require a “mapping service” mindset
- Limited APIs and export windows
- Vendor-specific formats
- Hard-to-change identifiers
- Mitigation: use CDC where it fits, build a canonical ID mapping service, document lineage, and ownership
A quality bar makes data extraction in telecom industry measurable
A practical quality bar should include:
- Duplicate rate thresholds per source
- Null/invalid identifier thresholds
- Drift thresholds (event_time vs ingest_time)
- Reconciliation checks (counts/totals vs upstream)
Privacy and compliance must be designed in on day one

You can’t bolt privacy onto telecom datasets after the fact.
Key controls:
- Data minimisation: ingest only fields required for the use case
- Pseudonymisation/tokenisation: protect identifiers in analytics zones
- Role-based access control (RBAC): enforce least privilege
- Retention policies: align with telecom regulations and contracts
- Encryption: in transit + at rest, with managed key policies
- Audit logging: who accessed what, when, and why
Define “red zones” explicitly:
- Raw CDRs with direct identifiers
- Location and signalling data with higher sensitivity
- Call recordings and transcripts
AI amplifies good pipelines and exposes bad ones
Use AI where it reduces manual work or improves detection.
- ML for anomaly analysis: detect KPI deviations by cell/service/region and prioritise by likely customer impact
- AI-assisted correlation: link repeated complaints to network events and suggest probable causes from history
- Predictive analytics: forecast demand and churn risk after experience degradation
Practical safeguards:
- Keep features interpretable for ops teams
- Version models and datasets together
- Monitor drift (network behaviour changes fast)
Build vs buy works best as a hybrid
“Buy” accelerates ingestion; “build” protects differentiation in correlation and governance.
Business model determines which datasets must be gold, and which can be good enough.
- Mobile and fixed-line operators
- Mobile: high event volume, mobility, device complexity
- Fixed-line: service assurance, provisioning journeys, regional constraints
- MVNOs and wholesale telecom providers
- Dependence on partner data quality
- Settlement and reconciliation are core workloads
- IoT and 5G platforms
- Massive device fleets and intermittent connectivity
- Security posture matters more (device identity, anomalies)
If you’re evaluating a data extraction company, start with what you want to own long-term (canonical model + quality layer).
If you’re comparing vendors, this overview of the best data extraction companies helps you ask better questions before procurement.
From Data Pipelines to Operational Decisions: Making Extraction Work
The goal isn’t “a data lake.” The goal is decision‑grade datasets with owners, contracts, and quality checks. Done well, data extraction for telecom becomes the operational backbone for network teams, customer care, finance, and compliance.
Practical Takeaway: Starter Checklist
- KPI is defined and stakeholders agree on the formula
- Source inventory mapped to correlation keys
- Canonical IDs and timestamp standards documented
- Data quality checks (duplicates/nulls/drift) implemented
- Privacy model (minimisation, RBAC, retention) approved
- One dashboard/API shipped that changes an operational decision
Finally, remember: data extraction in the telecom industry is a continuous capability, not a one‑time project. Treat datasets like products, and your analytics stops being “interesting” and becomes operational.
Want a concrete public example of how fast-moving telecom datasets can be delivered? Explore the real-time telecom research address case.
If your use case includes competitive pricing, coverage, or channel monitoring, read how web scraping drives data-driven telecom market research.
FAQ
-
What’s the difference between ETL and telecom data extraction?
ETL is a method (extract–transform–load). Telecom extraction is broader: it includes correlation across OSS/BSS, document parsing for bills, identifier mapping, and reconciliation. Extraction fails when ETL moves data, but nobody can prove completeness or consistency.
-
Which telecom data sources should we ingest first?
Start with sources that directly support a decision: CDRs/xDRs for usage truth, trouble tickets for customer pain, and billing outputs for revenue truth. If you can’t join these by time and identifier, build mapping tables and timestamp standards first.
-
Do we need real-time pipelines for telecom analytics?
Not always. Use real-time when your decision window is minutes (major incidents, fraud spikes). For churn modelling, planning, and regulatory reporting, batch pipelines are usually enough and simpler to operate.
-
How do we extract data from telecom bills and PDFs reliably?
Treat PDFs as unstructured data: use OCR and table detection, then normalise line items into a stable schema. Reliability comes from validation rules (totals, taxes, currency, duplicates) and a human review workflow for low-confidence cases.
-
What should we measure to prove a data extraction program is working?
Track reliability (duplicate rate, null rate, drift), coverage (percent of expected events captured), and business outcomes (reduced MTTR, fewer billing disputes, recovered leakage). Also measure time-to-answer for recurring questions.




