Client Story
Every time the team wanted to add a city or plug in a new data source, the pipeline broke. Not dramatically — but enough to eat up developer hours on what should have been routine work.
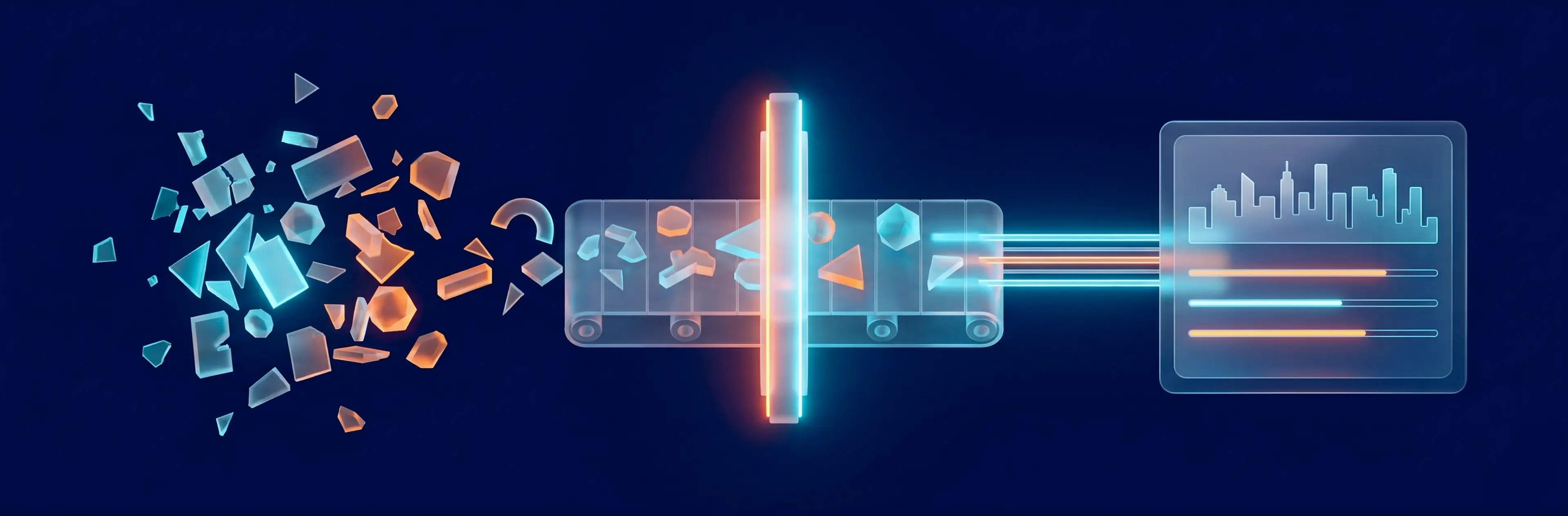
The platform’s Trend Machine (an AI scoring system that aggregates and ranks city data) pulls from 7 sources with different formats, update schedules, and reliability levels to score 30+ European cities across safety, gastronomy, transport, culture, and accommodation. Earlier parts of this series covered data collection and classification. This part is about the layer underneath — the ETL orchestration.
| Industry: | OTA (Travel) |
|---|---|
| Year: | 2025 |
| Location: | EU |
"Adding a new city used to mean touching every part of the pipeline. Now it's mostly configuration — database records and keyword setup. That's what lets us scale without scaling the team." — Co-Founder of travel startup
"Before the pipeline, every data update was a manual process — someone had to check each source, clean the data, and push it through. Now the scheduling system handles it, and we only intervene when something actually breaks." — CEO of travel startup
The Challenge: Orchestrating 7 Sources With Different Rhythms
Before the pipeline existed, every data update was a manual fire drill. A scraper breaks — someone investigates. A new city goes live — a developer touches six different parts of the system. A source changes its format — the whole refresh stalls. The team wasn’t building product; they were babysitting data.
Three problems made this especially hard to fix:
Sources that update on completely different schedules. Crime indices and transport connectivity scores change at most once per quarter. Reddit threads and TripAdvisor reviews generate new data daily or weekly. Refreshing everything at the same rate wastes compute on static data — and misses fresh signals from fast-moving sources.
No room for partial failures. A failed scraper run for one source shouldn’t block or corrupt aggregated scores for an entire city. The pipeline needed source-level isolation — where each source processes independently, and downstream aggregation consumes only validated data.
Scaling without re-architecture. The MVP launched with 30+ cities and 7 sources. The founders’ roadmap targets significantly more cities and new source types. Every new addition needed to fit the existing flow with minimal pipeline changes.
An ETL Pipeline Built for Incremental Growth
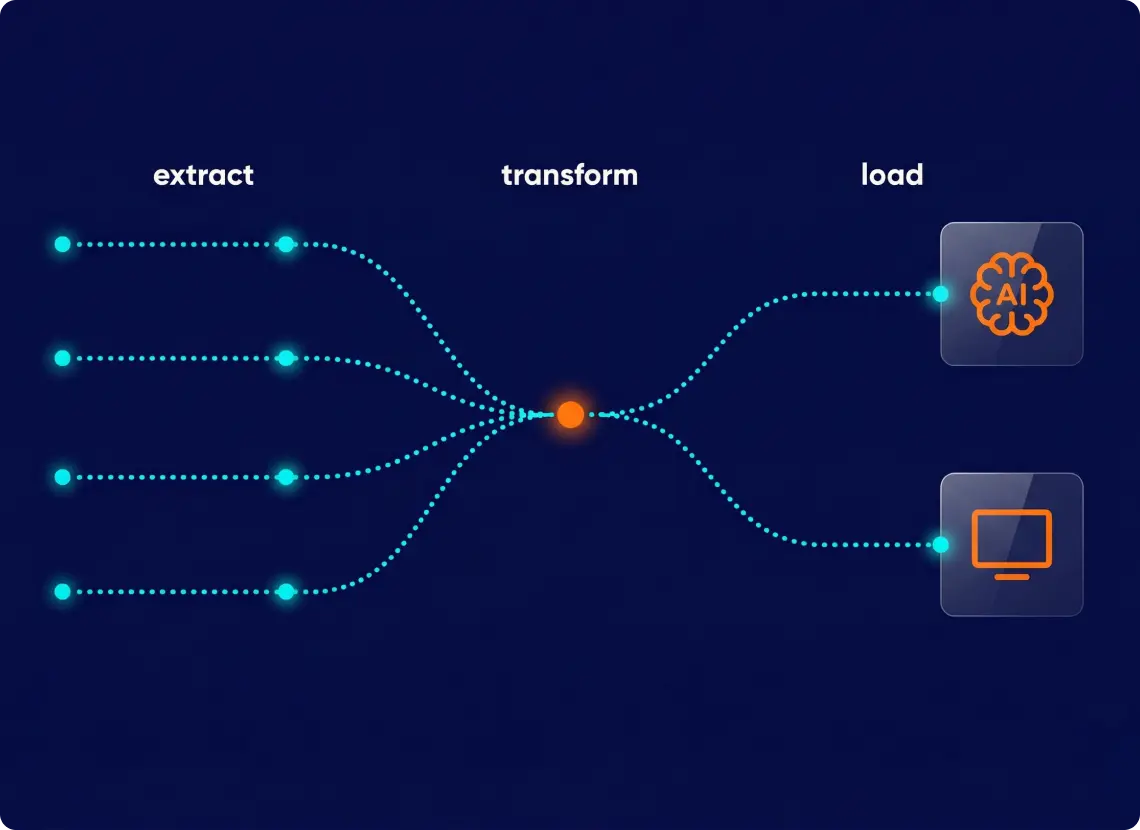
The pipeline works in three stages: pull data from each source → clean, classify, and score it → combine everything into city scores ready for production. Each source runs on its own schedule, independently, so if one breaks, the rest keep going. Results stay separate until the final step, when they merge into the scores that power the platform.
1. Each source runs independently — one failure doesn’t break the rest. Every data source has its own processing session. If Reddit goes down, TripAdvisor scores keep updating normally. The system logs each step automatically, and when something fails, it flags the exact record with a clear error message — so the team knows what broke and where, without digging through shared logs.
2. Each source refreshes on its own schedule. Not all data needs the same update frequency. Crime rates and airport connectivity barely change — they refresh quarterly. Reddit threads and TripAdvisor reviews move fast, so they update daily or weekly. The scheduling system manages each rhythm separately, so nothing gets refreshed too often or too rarely.
3. Processed data feeds two outputs: the AI content engine and the live front end. Once data clears processing, it splits into two downstream paths. The AI content engine uses it to generate editorial text for city pages — descriptions, summaries, category highlights. The front end consumes it directly to render live city scores. Because sources refresh at different cadences, both outputs always reflect the freshest available data: review-based scores update daily, while index-based scores update quarterly. The result is a platform where content and live data stay in sync — without manual coordination between the two.
Tech Stack: Python 3.12 · MySQL 8.0 · Celery + Redis (task scheduling) · Metabase (pipeline monitoring)
ETL isn't glamorous, but it's where pipelines live or die. Get the orchestration wrong, and every new source becomes a re-engineering project. Get it right and the pipeline grows by config.

From Manual Data Wrangling to Automated Pipeline
Source isolation in practice. When one scraper experienced extended downtime post-launch, the rest of the pipeline continued without interruption. The team diagnosed and fixed the issue without affecting live city scores from other sources.
What used to take a developer half a day now runs automatically on schedule. The automated pipeline means the startup doesn’t manage individual data flows manually. Sources run on their own cadences, errors surface with full context, and the team spends their time building new features — not babysitting the pipeline.
New cities and sources without re-engineering. Adding a new city involves configuring the database — city records, keyword setup, and source-specific parameters. Adding a new data source requires a new session type that follows the same extraction → processing → aggregation flow. The architecture accommodates growth without structural changes to the core pipeline.
Monitoring via Metabase. Dashboards track processing volume, error rates, and per-city data freshness. Alert thresholds flag anomalies — a sudden spike in failed records or a source that hasn’t delivered new data within its expected window. The founders see pipeline health alongside product metrics without needing engineering to interpret raw logs.
Service: Data Engineering | Next in series: Part 5 — Custom Software Development →

Need an ETL Pipeline That Grows With Your Product?
If your platform aggregates data from multiple sources with different formats and update rhythms — and you're tired of rebuilding your pipeline every time something changes — we've solved this problem before.




You have an idea?
We handle all the rest.
How can we help you?
