The Client Story
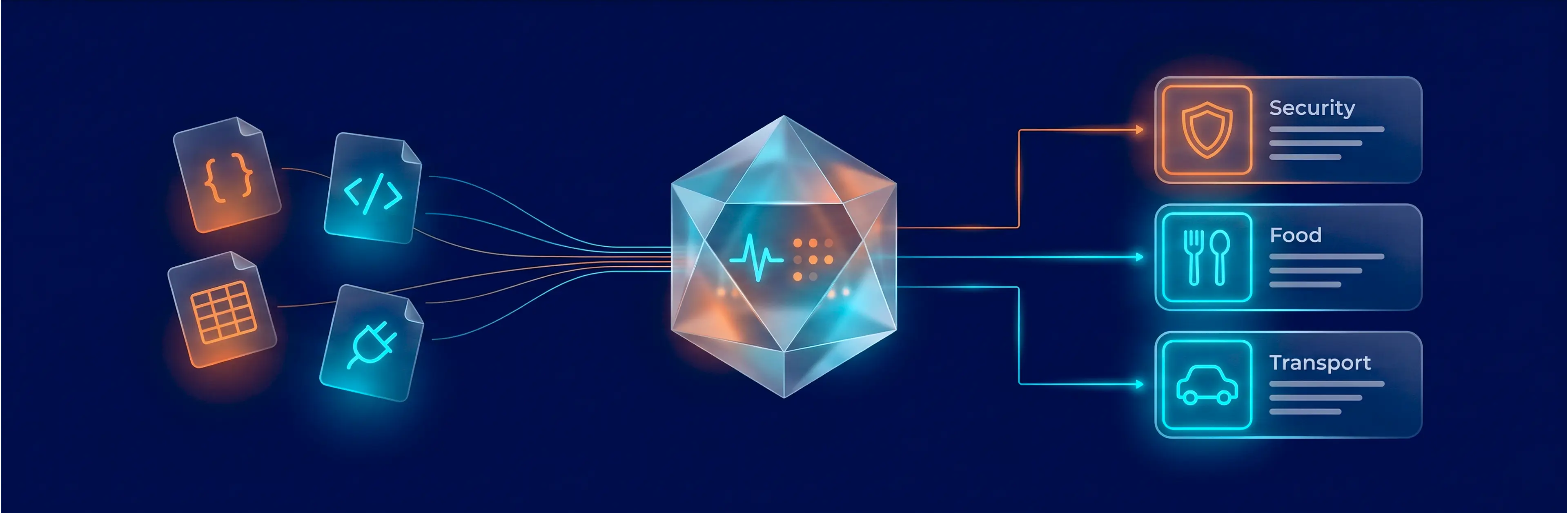
An EU-based travel startup built an AI platform that scores cities across five dimensions — safety, gastronomy, transport, culture, and accommodation. The platform’s core engine, the client’s proprietary Trend Machine, pulls raw data from 7 production scrapers: Reddit threads, TripAdvisor reviews, food rating sites, crime indices, and transport data.
The core problem: raw scraped data couldn’t feed the Trend Machine directly. A Reddit comment like “the tacos near La Rambla were insane” had to be recognized as a gastronomy signal for Barcelona, categorized, scored for sentiment, and written into the right database table — all before any LLM touches it. The client needed an engineering layer that could handle this transformation reliably and at scale. That’s where GroupBWT came in.
| Industry: | OTA (Travel) |
|---|---|
| Year: | 2025 |
| Location: | EU |
"Before the pipeline, we had thousands of raw reviews and no way to turn them into anything useful. Now we have structured city scores that update themselves." — Co-Founder of Travel Startup.
"The hardest engineering was everything before the AI: making sure the data arriving at the model is clean, categorized, and trustworthy." — CEO of Travel Startup.
The Challenge: 7 Sources, 5 Categories, Zero Shared Schema
The startup’s product promise was bold: score any European city across safety, food, transport, culture, and accommodation — and update those scores automatically. Seven scrapers were running. The Trend Machine was ready. Yet nothing connected the two — and without a reliable data pipeline, the platform had no product.
Four engineering problems stood between the client and launch:
No common structure — the root of every downstream problem. Reddit delivers nested JSON. TripAdvisor — HTML fragments. Numbeo — tabular CSVs. TomTom — REST API responses. Until these seven formats were unified into one schema, nothing else could work: no filtering, no classification, no scoring. Every challenge below traces back to this one.
Signal vs. noise at scale. Without structure, there’s no reliable way to separate travel signals from garbage. A post mentioning “Barcelona” might be about a football match rather than a travel experience. Unfiltered data wastes processing budget and produces unreliable scores.
Multi-category classification. “The metro was fast, but the area felt sketchy at night” spans both transport and safety. The pipeline needed to split and route these signals correctly without double-counting.
Confidence scoring. A 2024 safety index carries more weight than a 2019 blog post. The pipeline needed to flag low-data cities rather than generate scores from insufficient evidence.
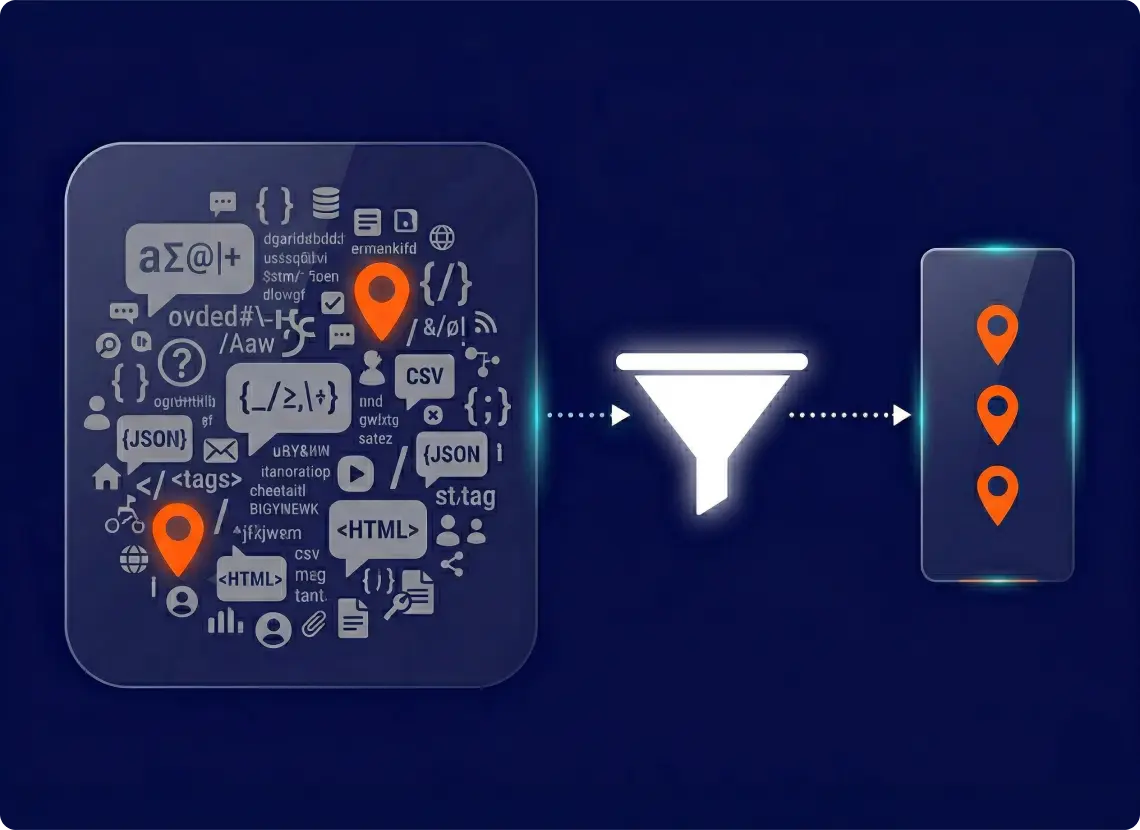
Multi-Phase Filtering & Classification Pipeline
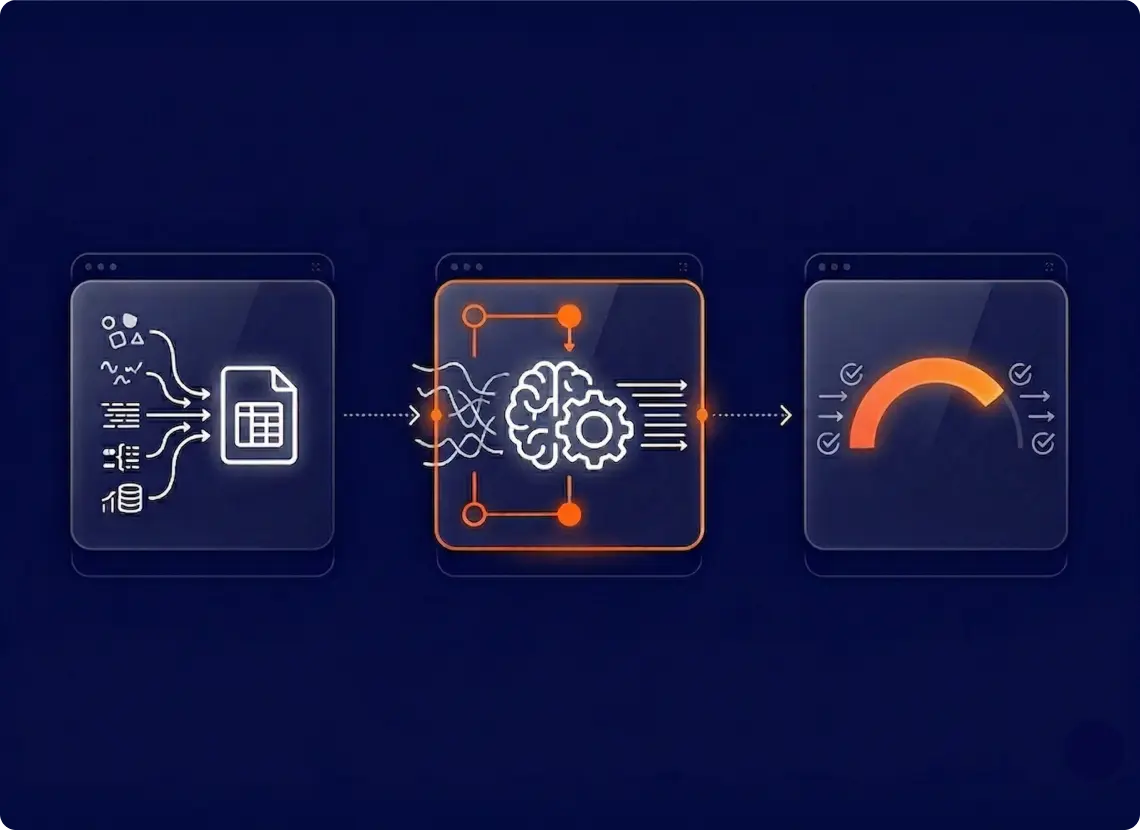
GroupBWT engineered a custom pipeline that sits between the scraping layer and the client’s AI content generation. Its job: raw data in from 7 different formats, clean confidence-scored records out.
Normalization. All scraped data is converted to a unified format — source ID, city mapping, raw text, timestamp, language tag — before any processing begins. Deduplication catches near-identical content across sources—preventing the client from paying AI processing costs for duplicate reviews.
Multi-phase filtering. The pipeline runs three processing phases: extraction, relevance classification, and category-level sentiment analysis. We implemented rule-based heuristics for the first pass — a highly effective, cost-saving measure that instantly filters out obvious spam and off-topic content, preserving the expensive AI compute budget for valuable travel signals.
Category classification and scoring. Filtered records are classified across the five scoring categories using a lightweight AI model. Records that span multiple categories (such as the metro/safety example above) are split into separate signals with appropriate weights. This increased scoring coverage by 20–30% per city, extracting maximum business value from every single review without needing to scrape more data.
Confidence scoring. Every city-category pair gets a confidence score based on record count, recency, and source diversity. When confidence falls below the threshold, the platform indicates lower reliability rather than showing a fabricated score. These flags also serve as the product roadmap — they tell founders where to deploy new scrapers.
Tech Stack: Python 3.12 · MySQL 8.0 · Redis (caching rapid requests to reduce database load) · Metabase (custom BI dashboards for operational visibility)
When you're processing hundreds of thousands of reviews, the temptation is to throw everything at an LLM. We took the opposite approach — rule-based filtering first, AI only where it adds real value. That's how you get $0.16 per city, not $16.

From Raw Noise to Structured City Scores
Maximized Signal Extraction. GroupBWT engineered the pipeline to extract maximum value from existing data. The client launched with richer city profiles than originally scoped — without expanding their scraping budget.
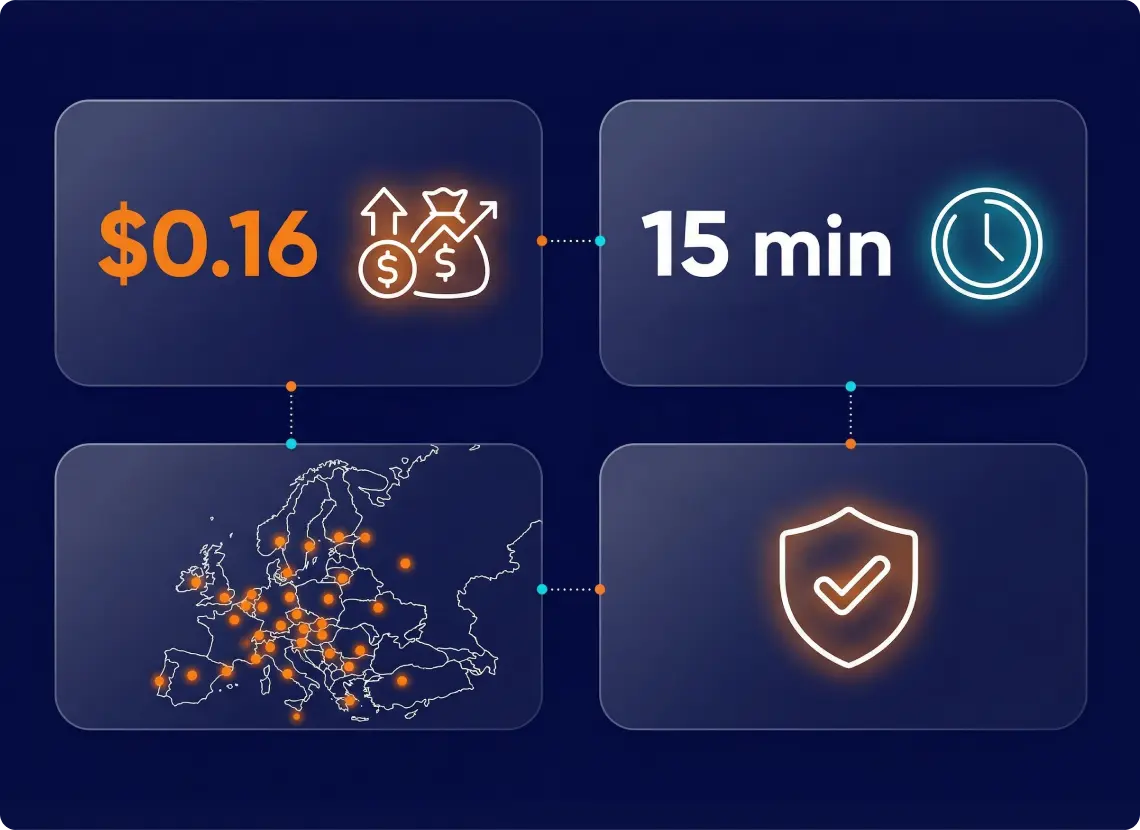
Scalable & Predictable Unit Economics. By handling the heavy lifting before the LLM step, the pipeline processes hundreds of thousands of records while keeping per-city compute costs at a highly predictable ~$0.16 per refresh cycle. A full 30+ city refresh completes in under 15 minutes.
Confidence and Trust. Low-confidence flagging prevents unreliable scores from reaching production. In thin-data cities, users see an honest confidence indicator rather than a fabricated number, protecting the platform’s reputation.
Total Transparency. We transformed raw pipeline logs into clear Metabase BI dashboards, giving the founders real-time visibility into data volumes, processing bottlenecks, and system health. Failed jobs retry automatically; persistent failures trigger alerts.
Service: Data Engineering | Next in series: Part 4 — ETL/ELT Pipeline →
Building a Product That Runs on Messy Data?
If your platform needs to turn unstructured content into structured, scorable data — without spending your entire budget on brute-force AI processing — we’ve built this before.
Talk to Our Team →
Ready to discuss your idea?
Our team of experts will find and implement the best eCommerce solution for your business. Drop us a line, and we will be back to you within 12 hours.




You have an idea?
We handle all the rest.
How can we help you?
