
The Client Story
A media-focused B2B platform—developed and maintained in-house—supports regional publishers across multiple cities. Built to help local media better identify, target, and serve municipal audiences, the platform hit a bottleneck: collecting timely, structured data from government sources.
One newly onboarded client needed high-frequency extraction from 40+ city-level sites, including city halls, public notices, and event boards. With 10+ new clients planned (1,500–2,000 sources), the platform turned to a vendor to build and operate the full scraping architecture and scaling logic.
| Industry: | Legal Firms |
|---|---|
| Cooperation: | Since 2024 |
| Location: | Europe |
Our team could build the platform—but building and maintaining a 2,000-source scraper wasn’t a battle we could afford.
We needed daily insight into municipal events, tenders, policy changes—but didn’t want to maintain fragile scrapers.
Why This Client Needed Legal-Grade News Intelligence
A regional B2B media platform needed to serve legal and public sector clients who required reliable, high-frequency access to municipal news. But the data needed—event calendars, city notices, government updates—was scattered, unstructured, and manually tracked.
The platform’s in-house team lacked the data infrastructure, so they hired GroupBWT, an external vendor, to engineer and operate it end-to-end.
- 40+ public sources across local governments, each with unique layouts, CMS logic, and no APIs
- No authentication required, but extreme markup variability made structured extraction fragile
- 3–5 scrapes per day required per source, including weekends and off-hours
- 50× scalability goal within 12 months—from 40 to 2,000 sources, with zero re-architecture
- JSON output + optional API delivery, fully automated, with no internal maintenance burden
Our system replaced manual tracking with a resilient, self-monitoring aggregation pipeline—built to scale, and ready for legal use cases from day one.
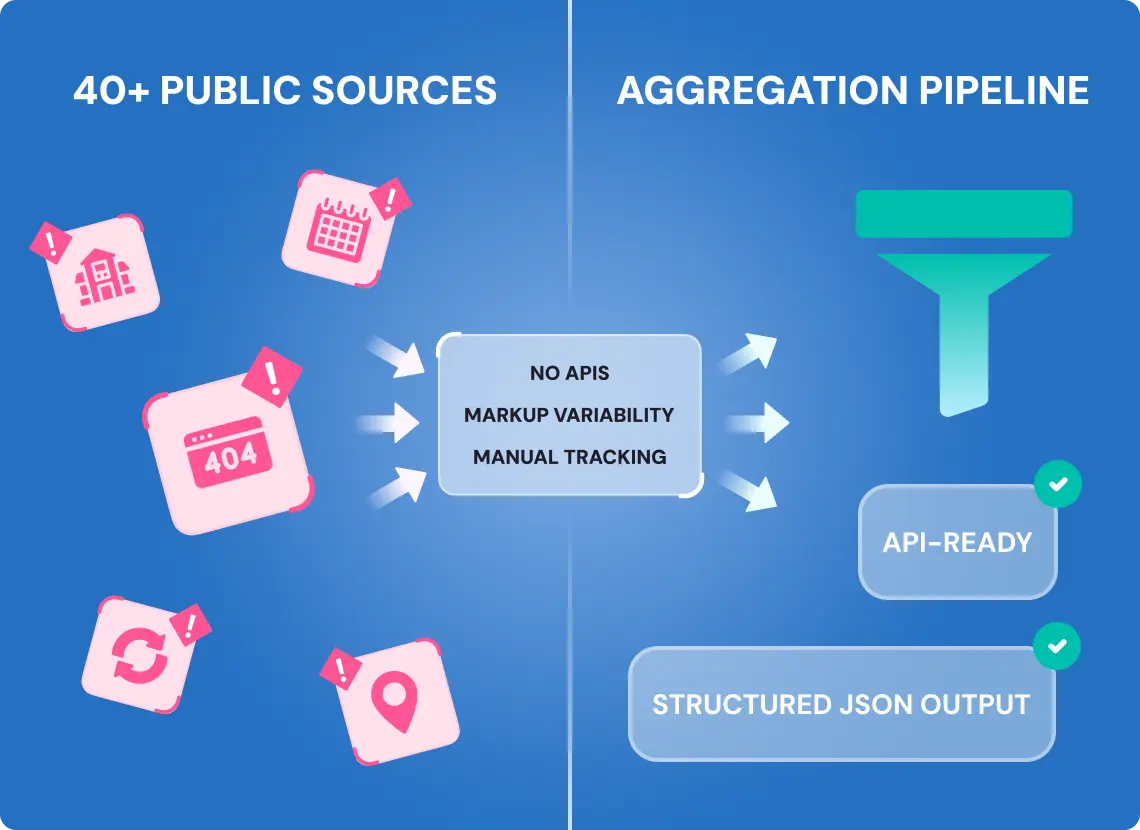
Legal-Ready News Aggregation Built to Eliminate Manual Monitoring
We developed a full-cycle content extraction system tailored for municipal and legal news aggregation, with minimal maintenance, high-frequency delivery, and a structured format from day one.
Unified Parsing System
To handle 40+ city websites with inconsistent markup, we engineered a normalization-first extraction logi
- Used Scrapy for simple static websites
- and Playwright for dynamic content loading and stronger anti-bot protection
- Automatically classified collected content into event updates, city notices, and tender announcements, using rule-based and contextual tagging logic
- Collected the same structured fields across all sites, despite differences in layout
- Ignored unchanged content with built-in duplication filters
- Delivered clean JSON with exact timestamps and source URLs
→ Legal analysts receive uniform, ready-to-use news records—no HTML cleanup needed.
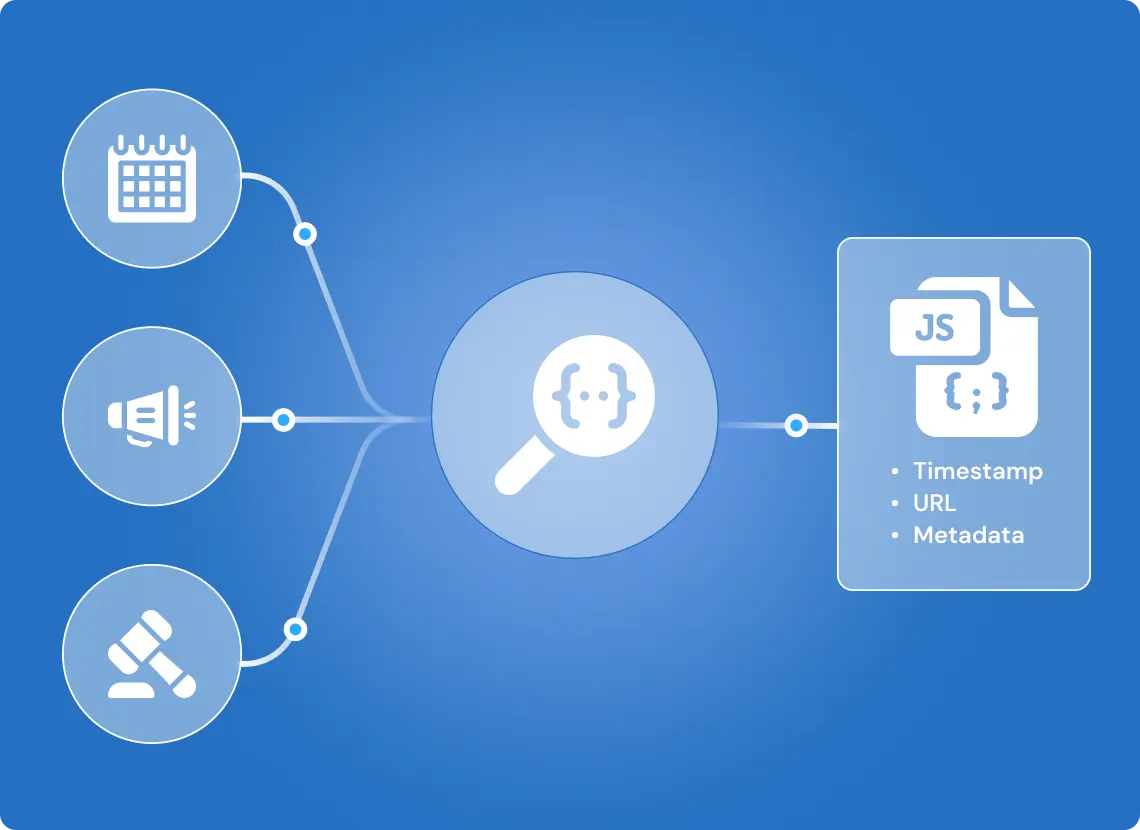
GroupBWT delivered a system with scale logic, monitoring, and API-ready output from day one.

Expansion Without Code Changes
The system is designed to grow from dozens to thousands of sources without architectural rewrites.
- New sources are added via YAML configuration files, where selectors, metadata rules, and scheduling are defined — no code modifications required
- Concurrent scraping is orchestrated through an async job queue, allowing hundreds of extractions to run in parallel
- Scraper jobs are split by region, enabling granular control and resource allocation
- Supports both daily runs and instant updates
- Scales from 40 to 2,000+ websites using the same core infrastructure
→ Add 100 new sources in 2-3 days–no code rewrites, no extra dev team.
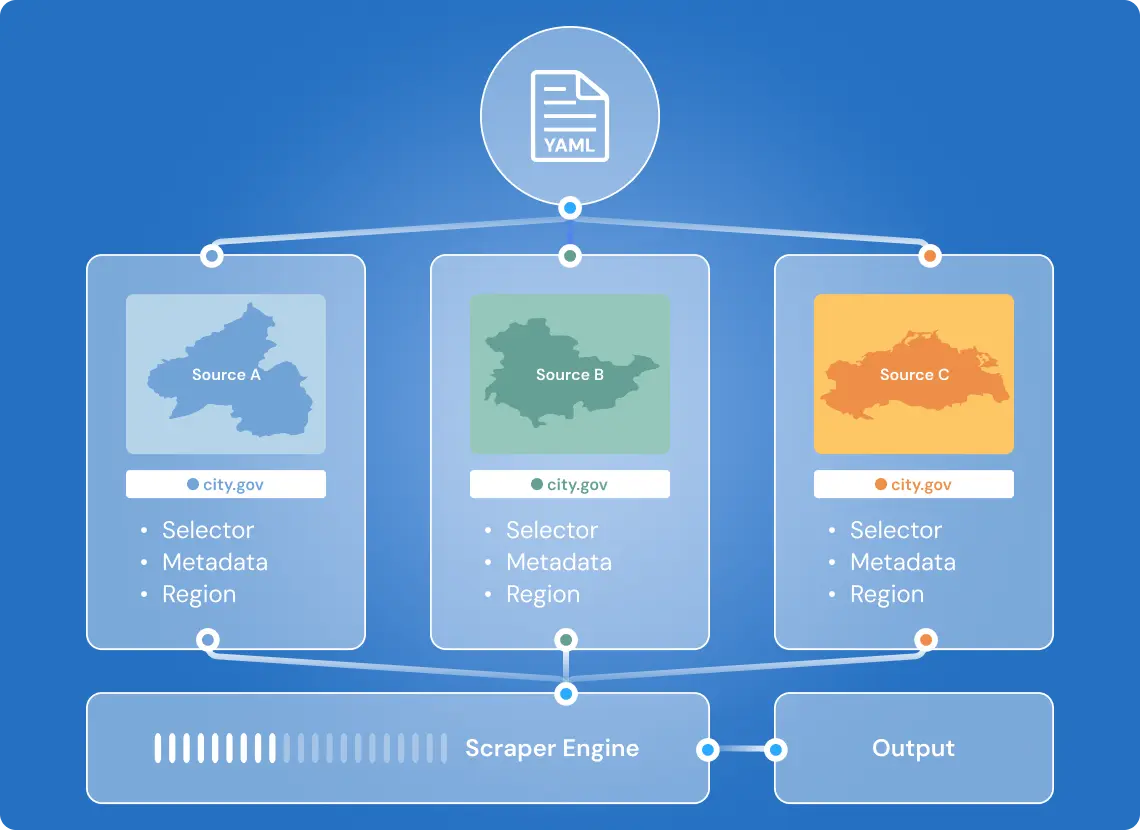
Automated QA and Retry Logic
Every extraction run is tracked, verified, and auto-recovered if needed.
- Dashboard with logs, success rates, and retry stats per domain
- Failed attempts are retried within 10 minutes
- Alerts fire after 3 failed runs per day, per source
- Output is continuously validated for completeness and formatting
- Data logs are stored for audits and post-run inspection
→ You never lose news, even if a city page goes down temporarily.
Delivery Into Your Legal or BI Systems
Output is designed for seamless intake, whether by legal tools or internal dashboards.
- JSON-formatted metadata with source, timestamp, and article title
- Optional API push to third-party or internal systems
- Multi-client ready: assign separate feeds per recipient
- Supports both real-time and scheduled delivery
- No personal data collected—fully GDPR-compliant by design
→ Your legal platform receives daily updates without scraping, delays, or compliance risks.
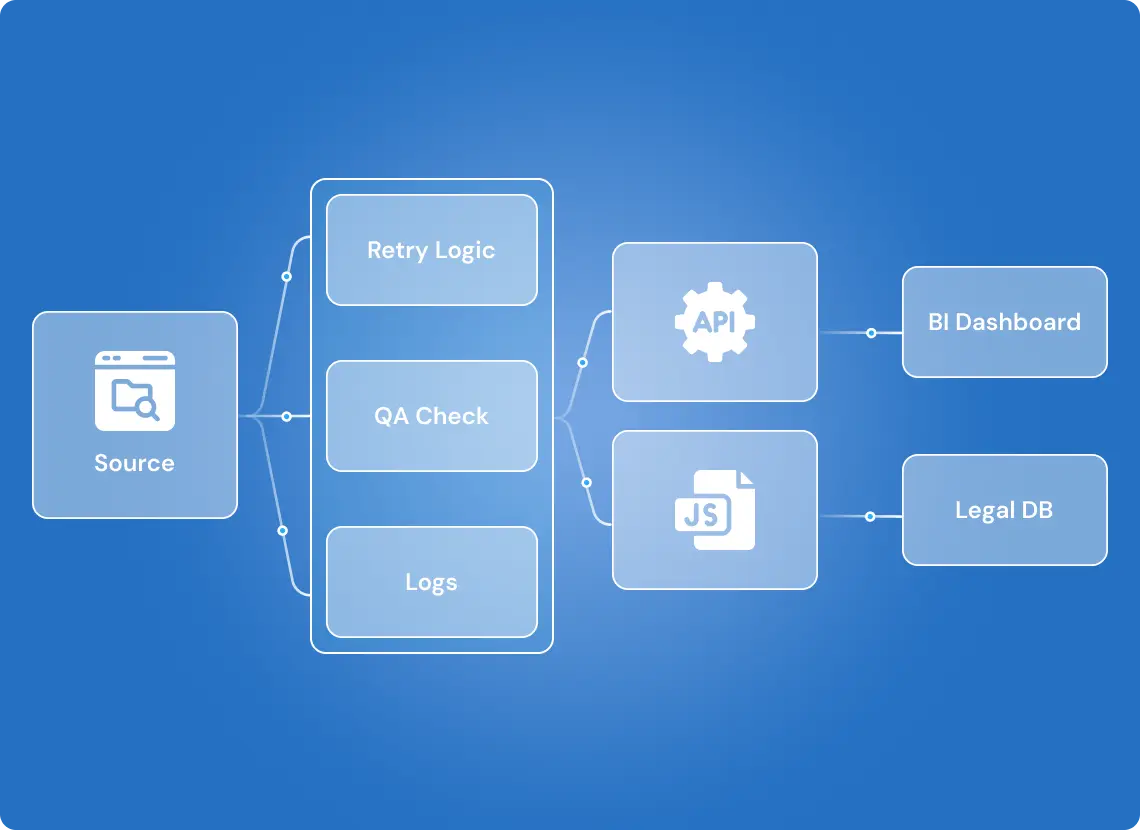
1,000+ Manual Hours Eliminated in Legal News Monitoring
What began as a fragile manual workflow became a reliable, zero-maintenance content backbone—ready to serve legal and public sector clients with speed, precision, and compliance built in.
The system was architected as a modular template, ready to support future clients with similar legal or civic monitoring needs, without rework.
Built-In Gains: Faster Onboarding, Cleaner Data, Zero Ops Load
- 12× faster onboarding → enables market expansion without growing the ops team
- 5× increase in content freshness → daily syncs vs. weekly crawls
- Zero team overhead → no internal FTEs involved in parsing or maintenance
- 99% data usability> → fully structured fields, no preprocessing required
- Full audit visibility → scrape logs, retries, error reports retained for review
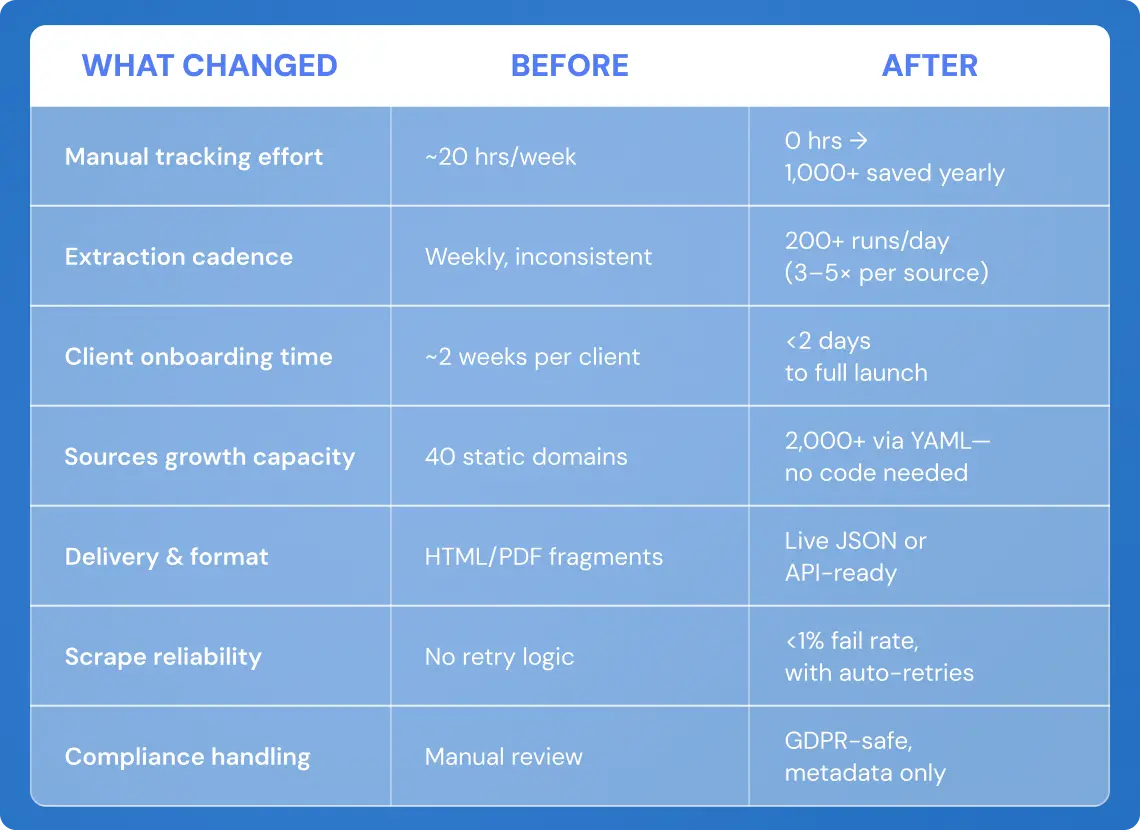
How We Scaled from 40 to 2,000 Sources
Instead of hardcoding each scraper, we built a YAML-based configuration layer. Each new source was added by defining a structured config file specifying:
- URL patterns and selectors for target content
- Extraction frequency and content type (event, notice, update)
- Layout fingerprinting rules for template matching
This approach allowed new government or city websites to be integrated in hours, not days—even if their HTML structures differed. When a known layout was detected (e.g., common CMS templates), we reused existing scraping modules.
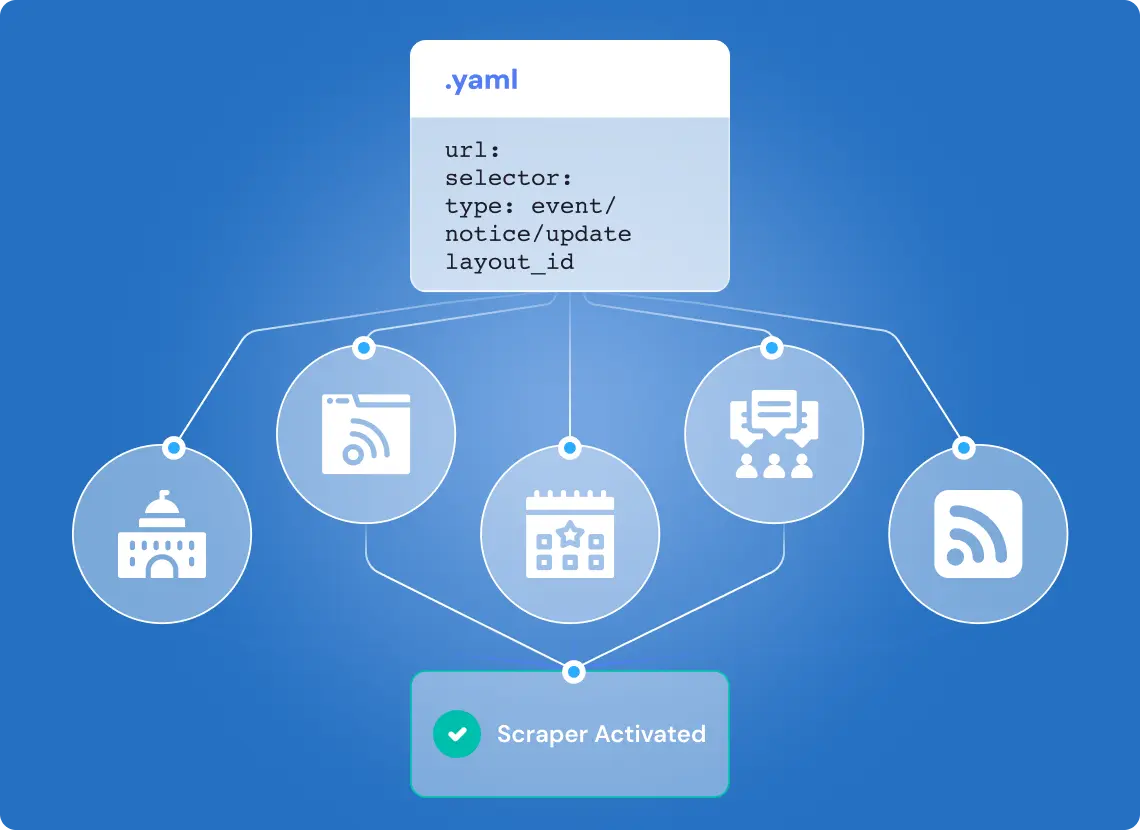
How We Made the System GDPR-Safe
Previously, personal data filtering was handled manually. We replaced that with automated entity detection and exclusion:
- Named Entity Recognition (NER) flags names, emails, and phone numbers
- All identified PII is removed or anonymized before saving/export
- Exceptions are logged in audit mode for review
This ensures the system operates within GDPR constraints without sacrificing update speed.
Looking to power your media, legal, or civic platform with a reliable data infrastructure?
Let’s build your custom scraping system—engineered for growth, not breakdown.
Ready to discuss your idea?
Our team of experts will find and implement the best eCommerce solution for your business. Drop us a line, and we will be back to you within 12 hours.




You have an idea?
We handle all the rest.
How can we help you?
