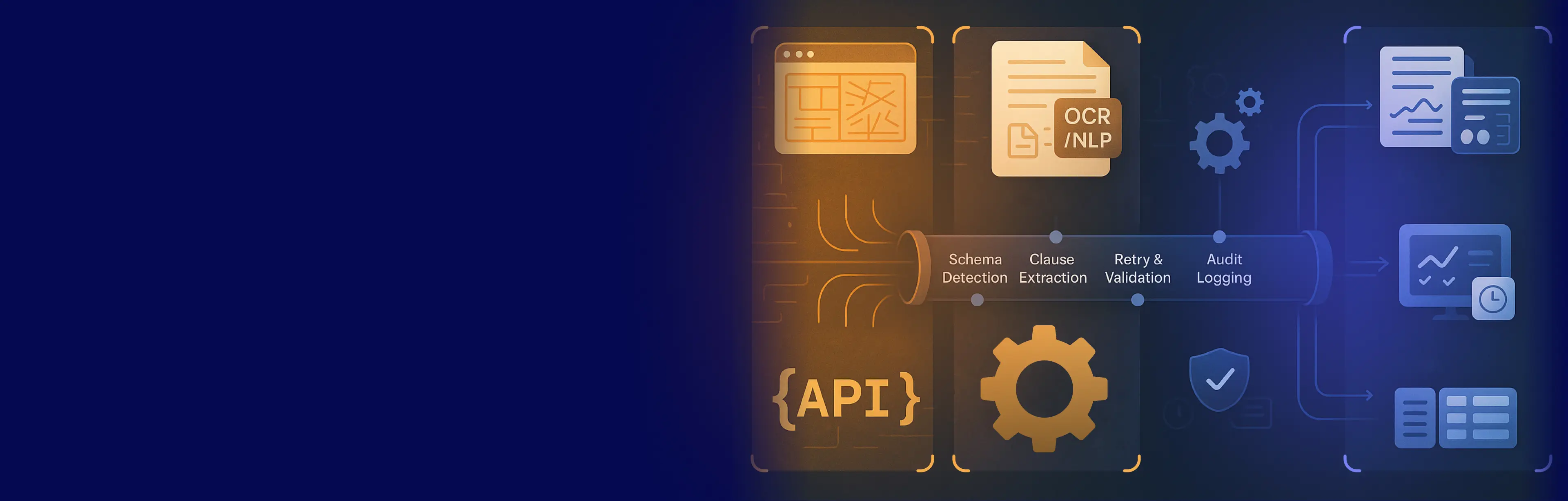

Firms no longer extract data for reports—they extract data to run their business. Every lease, listing, or tenant event becomes a datapoint that fuels underwriting engines, CRM triggers, valuation models, and investor dashboards. The goal isn’t to collect information. It’s to automate insight delivery and decision execution.
How Modern Real Estate Data Extraction Works Today
To achieve this, modern real-time teams rely on three interconnected data extraction pillars:
1. Web Scraping for Dynamic Listings and Comps
Most commercial listing platforms—from marketplaces to agency websites—don’t offer complete APIs. Even when APIs exist, they often:
- Lag behind the UI by hours or days
- Miss critical metadata (e.g., photos, agent contacts, temporal changes)
- Fail to flag removals or stale listings
That’s why web scraping remains essential. But not as brittle scripts. In 2025, scraping uses:
- Headless browsers to capture JavaScript-rendered content
- Schema-aware crawlers that adapt to markup drift
- Version control to track changes over time
This ensures daily extraction of pricing trends, property availability, and market shifts—directly from source-of-truth interfaces.
2. OCR for Lease Documents and PDF-Based Records
Most lease documents, amendments, and zoning approvals still arrive in PDF or scanned form, locked away from AI models. These days, leading teams will solve this with:
- Document parsing engines powered by OCR (Optical Character Recognition) + NLP (Natural Language Processing)
- Clause-level extraction for rent escalations, co-tenancy triggers, and renewal rights
- Confidence scoring for ambiguous fields
Structured lease metadata flows directly into underwriting tools, audit logs, and compliance systems—no manual entry required.
3. APIs for Real-Time Sync and Partner Feeds
Where structured endpoints exist, APIs are used to:
- Ingest partner listings and broker feeds
- Sync IoT data from building management systems (HVAC, access logs, meters)
- Track changes in zoning, taxation, or government registries
The key isn’t just calling the API. It’s building resilient ingestion pipelines that handle:
- Rate limits
- Payload shifts
- Timestamp versioning
- Upstream outages
This lets real estate platforms keep their dashboards up-to-date, without refresh lag or reconciliation delays.
If this sounds like a lot to manage, it is. That’s why the best teams break it down into manageable systems, not scripts.
How CRE Teams Automate Decisions Nowadays
In legacy systems, data extraction was an analyst’s job. In 2025, it’s a live function inside the transaction system. The pipeline itself is the product.
At GroupBWT, we build end-to-end data extraction infrastructure that supports:
- Real-time listing change detection
- Lease document digitization
- API-based ingestion of external and IoT data
- Cleaned, validated, and schema-tagged outputs
- Direct delivery to CRMs, valuation engines, and compliance logs
CRE Asset Types Supported in Modern Extraction Pipelines
Commercial Real Estate (CRE) refers to income-generating properties used for business purposes, not private housing. In the context of real estate data extraction, this segment is both the most complex and the most valuable.
Unlike residential markets, CRE involves longer lease terms, larger capital flows, and stricter regulatory oversight. That makes data completeness and auditability mission-critical.
Note: “CRE” also refers to “Carbapenem-Resistant Enterobacterales” in medical databases. In this context, we always mean Commercial Real Estate.
CRE Property Types Covered in Extraction Pipelines
The following asset classes fall under the commercial real estate data extraction umbrella and are actively extracted, parsed, and modeled:
- Office buildings (corporate HQs, coworking spaces, mixed-use towers)
- Retail properties (malls, strip centers, high-street stores)
- Industrial sites (warehouses, logistics centers, distribution hubs)
- Multifamily rentals (5+ unit buildings, REIT-managed complexes)
- Hospitality assets (hotels, serviced apartments, resorts)
- Special-use facilities (data centers, life sciences labs, healthcare campuses)
CRE also includes land parcels under development, sites with zoning overlays, and high-density mixed-use projects.
How Is Commercial Real Estate Data Extracted?
Real estate data extraction in 2025 is no longer about scraping isolated websites or parsing PDFs ad hoc. It’s a production-grade infrastructure problem—one that requires hybrid, resilient, and compliant systems. Most commercial property data remains locked in semi-structured sources: HTML listings, scanned leases, internal Excel sheets, and fragmented APIs. To turn this into operational intelligence, CRE teams build robust pipelines—combining scraping, OCR, and real estate API data extraction—with validation, retry logic, and auditability by default.
1. Scraping Real Estate Marketplaces
When APIs are missing or outdated, browser-based crawlers become the primary tool to extract real estate data. These scrapers don’t just parse static HTML—they simulate real user sessions to capture dynamic, JavaScript-rendered content, often protected by geo restrictions or markup drift.
Key extraction techniques:
- Headless browser emulation (e.g. Playwright)
- Schema-aware selectors with change detection
- Delta tracking to log listing status changes over time
- Region-based proxy routing to comply with local terms
This is how top firms solve how to extract data from real estate websites at national or municipal levels—where structured access is unreliable or unavailable.
2. OCR for Lease Documents and Legal Clauses
Leases, zoning letters, and building permits are often distributed as PDFs or scanned image files. That makes them invisible to conventional parsers. OCR transforms these unstructured records into structured lease data streams.
Pipeline includes:
- OCR preprocessing (deskewing, denoising)
- NLP-based clause segmentation (e.g., rent escalations, exclusivity)
- Confidence scoring per extracted field
- Fuzzy logic to resolve tenant names and start dates
Each output is structured and tagged—feeding directly into underwriting, CRM, or compliance systems.
3. Underwriting Engines Demand Structured Inputs
Modern CRE underwriting engines ingest dozens of data types in real time:
- Lease terms: base rent, CAM charges, renewal rights
- Listing data: pricing, comps, property class
- Tenant profiles: payment history, credit risk, break clauses
- Asset health: maintenance logs, IoT sensors
- Market context: cap rates, inflation, vacancy trends
Without structured ingestion, these models fail. And without pipelines, structured ingestion doesn’t scale.
That’s why browser collectors, OCR layers, and API calls must work in tandem—with validation schemas and monitoring at every stage.
4. Real Estate APIs and Hybrid Fallback Logic
Where available, real estate data extraction APIs provide structured payloads—often cleaner and more complete than scraping. They enable ingestion of:
- Listing statuses and metadata
- Portfolio hierarchies (property, owner, unit mix)
- Real-time updates to CRMs or valuation models
But API coverage remains limited.
According to PwC, only 25% of real estate firms have APIs ready for production use. That’s why a fallback hybrid pipeline is essential.
Fallback orchestration includes:
| {
“source_order”: [“api”, “scraper”, “ocr”], “failover”: true, “log_source”: true } |
Even when APIs exist, they often lack asset-level granularity, miss listing removals, or break without version tracking.
5. Real Estate Data Extraction Is Now Infrastructure
To summarize: real estate data extraction today is not a script—it’s an orchestrated system. At GroupBWT, we build CRE pipelines that:
- Scrape listing portals with compliance-safe automation
- Parse lease documents with clause-level OCR and NLP
- Ingest APIs where possible, with fallback logic
- Validate, structure, and stream outputs to underwriting engines and CRMs
- Maintain audit trails, retries, and schema monitoring at scale
In a market where milliseconds and missed clauses can change valuations, data extraction isn’t the first step. It’s the core of your operating engine.
Why Most Real Estate Pipelines Fail in Production
Even in 2025, most commercial real estate teams still struggle to operationalize data extraction. The reason isn’t a lack of tools—it’s the fragility of internal processes.
Outdated Workflows Block Revenue and Compliance
Most CRE firms still rely on:
- Manual lease reviews
- Ad hoc listing checks
- Spreadsheet-based data transfers
These workflows introduce latency, human error, and audit risk. When underwriting pipelines depend on emailed PDFs or legacy ERPs, deals stall, and regulatory exposure increases. Without structured extraction, revenue is delayed and compliance suffers.
Manual Data Entry Can’t Scale With Growth
As portfolios expand, so does the data load:
- New listings from multiple marketplaces
- Dozens of scanned lease amendments monthly
- Daily tenant ops data from IoT systems
Entering this manually is not just slow—it’s unsustainable. One broken cell or missed clause can skew a valuation or void a rent clause. Scaling without automation leads to burnout, inconsistency, and delayed insights.
Platform Changes Break Brittle Scripts
CRE listing sites, agency platforms, and public registries change their HTML frequently. That breaks legacy scrapers built with:
- XPath selectors hardcoded to fixed layouts
- One-off scripts with no retry logic
- No monitoring or schema drift detection
The result? Missing listings, wrong pricing, or silently broken feeds. Firms relying on brittle codebases spend more time debugging than extracting, and the data gaps compound silently in models and dashboards
Why CRE Firms Replace Scripts with Infrastructure
In commercial real estate, what you see on listing platforms, lease PDFs, or valuation dashboards is only a fraction of what’s there.
The 2025 Proptech AI report by Europe Real Estate reveals over €10B in expected AI deployment across CRE. But yet, structured pipelines simply don’t exist in most firms. AI readiness is low. And APIs miss half the signals.
Real Estate’s AI Bottleneck Is Unstructured Data
According to McKinsey & Company, generative AI is set to unlock $110B–$180B in value across real estate by transforming pricing, underwriting, tenant ops, and asset management.
But here’s the blocker:
“Only 14% of available real estate data is AI-usable.”
The problem isn’t model quality—it’s pipeline fragility. Data is trapped in scanned leases, outdated listings, email threads, and siloed Excel sheets.
“It wasn’t the tools that failed us. It was the fact that nobody monitored when the structure changed.” — VP of Data, CRE firm (anonymized)
To break through, firms must:
- Extract real estate data from marketplaces, lease documents, IoT feeds, and site reports
- Adopt data extraction software for real estate that auto-structures and tags key variables
- Build data stacks that flow into underwriting models, CRM triggers, and dynamic pricing engines
Scraping isn’t secondary. It’s the prerequisite to AI-readiness in commercial real estate.
Most Retail Firms Still Don’t Have Production-Ready APIs
PwC reports a massive readiness gap:
“85% of firms say AI and automation will redefine real estate strategy—but fewer than 25% have production-grade extraction APIs.”
Most are stuck in pilot mode, blocked by:
- Legacy ERPs
- Manual workflows
- Fear of non-compliance
Best-in-class teams are moving fast by:
- Deploying modular real estate extraction API layers
- Extract data from real estate websites using hybrid crawlers and OCR logic
- Auto-validating lease clause structures and asset metadata for underwriting
The difference? They treat data extraction as a compliance-first infrastructure, not scripting.
What Real Estate Data Teams Extract—And Why It Matters
In 2025, it’s not enough to extract fields. Teams need meaning: risk signals, pricing anomalies, lease obligations, and legal triggers. Legacy scraping tools failed because they lacked context. Modern pipelines—like those built at GroupBWT—translate unstructured sources into machine-usable logic.
For example:
- A CAM charge misclassified can distort NOI forecasts.
- A missed renewal option can cost millions in mispriced exits.
- A listing dropped for 24 hours can signal hidden negotiations.
From Raw Data to Revenue Impact
| Extracted Element | What It Solves | Why Automation Wins |
| Base Rent & Escalation Clauses | Pricing projections, NOI forecasting | Clause parsing avoids manual misreads in 20–40 page leases |
| Co-Tenancy & Termination Rights | Risk exposure during anchor tenant moves | NLP-based detection avoids missed risk clauses |
| Listing Price & Property Status | Real-time market visibility | Browser-based crawlers detect price drops within 6–12 hours |
| Unit Size, Amenities, Parking | Fair market valuation & comp selection | HTML parsers normalize listing attributes across sources |
| Building Permits & Zoning Data | Feasibility studies, development risk | Registry extraction automates change tracking |
| Utility Charges & Operating Expenses | Tenant pass-through validation | IDP matches scanned bills with lease terms & payments |
| Tenant Names & Lease Start Dates | Occupancy analysis, lease-up status | OCR + fuzzy matching improves CRM sync by 30–50% |
| Agent Contact Info & Listing Metadata | Lead routing, brokerage performance analysis | Real estate data extraction ensures clean contact sync |
| CAM Charges & Renewal Options | Cost forecasting, lease negotiations | Clause-level OCR parsing removes the need for paralegal review |
| Historical Sale Records | Asset valuation benchmarking | API + scraping combo fills in gaps from partial registries |
That’s why our custom systems:
- Tag every clause with context and fallback
- Run delta diffing to detect market shifts
- Log every decision variable with a timestamped proof
When valuation depends on precision, structured context extraction becomes the foundation of compliance, accuracy, and speed.
Legacy Workflow → Risk → Our Fix
| Legacy Workflow | Risk Introduced | GroupBWT |
| Manual lease review (PDFs, scans) | Missed clauses, delayed underwriting | OCR + NLP clause-level extraction pipelines |
| One-off scrapers with hardcoded selectors | Silent feed failures, missing listings | Schema-aware crawlers with version control + delta detection |
| Spreadsheet-based data transfers | Input errors, no audit trail | Structured API + auto-validated output to CRM/valuation stack |
| Ad hoc listing checks across platforms | Incomplete market visibility | Daily multi-source scraping + real-time alerting |
| No centralized ingestion layer | Disjointed data, broken automation loops | Modular ingestion hub with legal fallback + retry logic |
Treat data pipelines as infrastructure, not scripts. That’s how we help CRE firms unlock real-time insight, not just raw data.
What Modern CRE Data Systems Must Include
The world’s most advanced real estate teams are quietly shifting to enterprise-grade extraction architectures. These aren’t bots. They’re pipelines.
- Geofenced collection
- OCR + HTML hybrid scrapers
- Lease clause parsing
- Audit-aligned session logs
- API-linked delivery to BI stacks
They don’t just extract real estate data—they make it ready for pricing, compliance, and investor reporting.
What’s Extracted: Structured Wins
When done right, data extraction in real estate surfaces the variables that legacy tools miss:
- Square footage anomalies between listings and documents
- Clause-level lease risks (e.g., co-tenancy triggers)
- Market-specific pricing suppressions based on location or property class
- Temporal gaps in vacancy reporting
- Dynamic listing changes exposed via APIs
This isn’t bonus data. It’s the foundation of revenue models, compliance safeguards, and underwriting accuracy.
How We Structure CRE Data for Decision-Making
At GroupBWT, we build the connective layer between what the browser sees and what the valuation engine needs.
We help real estate teams:
- Extract data from real estate websites with full legal coverage
- Automate clause parsing from scanned documents
- Monitor listings with dynamic frontends
- Feed everything into analytics tools—without human touchpoints
From scraped leases to structured insights, it’s all handled through one architecture.
Why Real Estate Intelligence Starts With Extraction
- The future of CRE depends on systems that can:
- Extract data from unstructured sources
- Clean it, validate it, and track lineage
- Push it into models without manual handling
- Prove auditability and compliance
And that means:
Real estate data extraction is the core of modern commercial real estate intelligence.
How to Extract Data From Real Estate Websites: Case Studies
All use cases shown are based on real commercial real estate deployments delivered by GroupBWT. Due to the sensitive nature of property, compliance, and investor operations, client names and implementation details are anonymized under strict non-disclosure agreements (NDAs).
Outcomes, metrics, and methods reflect actual production environments, tested at scale.
Parsing Lease PDFs to Accelerate Underwriting
Problem: A CRE fund processed 10,000+ scanned lease agreements weekly. Manual review of base rents, escalation clauses, and co-tenancy terms delays underwriting decisions by 2–3 business days.
Solution: GroupBWT deployed OCR + NLP-based parsing engines to extract clause-level data directly from PDFs. Each document was tagged, validated, and streamed into underwriting workflows.
Impact:
- Processing time cut from 3 days to 40 minutes
- 10,000+ documents parsed weekly
- Zero-touch delivery to decision models
Aggregating Listings Across 50+ Rental Platforms
Problem: A proptech startup needed a live feed of all listings across 50+ European rental sites—most of which lacked reliable APIs and changed markup weekly.
Solution: We deployed a dynamic web scraping infrastructure with schema detection, retry logic, and daily delta capture. Scrapers were browser-based and geofenced to meet local compliance.
Impact:
- 1.5M listings ingested daily
- 99.3% field-level accuracy
- Enabled real-time pricing, inventory, and market demand dashboards
Real-Time API Sync for CRM and MLS Integration
Problem: A national brokerage firm operated disjointed systems for listings, lead management, and underwriting. Delays in sync led to stale inventory and missed client triggers.
Solution: GroupBWT built real estate data extraction APIs with webhook-based sync. Listings, agent updates, and property metadata flowed into Salesforce and underwriting engines in near real time.
Impact:
- End-to-end sync latency reduced from 6 hours to 45 seconds
- CRM triggers are automated based on listing status and pricing delta
- The deal closing rate increased by 27%
Merging Utility Bills and Tenant Payment Histories
Problem: A residential property manager received thousands of scanned utility bills monthly. Manual reconciliation with tenant payments took days and led to billing disputes.
Solution: Our IDP pipelines combined OCR with fuzzy logic to extract utility charges and match them with tenant IDs and payment logs. Structured reconciliation reports were generated automatically.
Impact:
- 5,000+ bills processed monthly
- Dispute rate dropped by 84%
- Reconciliation reduced from 4 days to 6 hours
Real-Time Benchmarking of New Developments
Problem: A CRE investment team lacked visibility into new development projects, relying on static reports and outdated public data.
Solution: We deployed commercial real estate data extraction pipelines to scrape registries, developer sites, and listing portals. Real-time updates on new units, permits, and pricing were injected into valuation models.
Impact:
- Continuous tracking of 1,200+ developments
- Time-to-update cut by 60%
- Enabled dynamic valuation and underwriting precision
How Real Estate Data Feeds Decision Engines
To make decisions in real time—not weeks later—modern real estate systems need structured data at the input level.
|
[ Decision Engine ] ▲ [ Structured CRE Data ] ▲ ▲ ▲ [OCR] [Scraping] [APIs] |
Each layer plays a role:
- OCR unlocks lease clauses and scanned records
- Scraping captures listing deltas and visual-only metadata
- APIs sync live partner data and platform updates
Together, they generate timestamped, validated, compliance-ready inputs for valuation engines, CRMs, and investor dashboards.
Real Estate Use Cases: Explore Services & Solutions
| Related Insights | Why It Matters for Real Estate |
| Content Aggregation Services | Power real-time feeds from fragmented listing portals, PDF docs, and IoT sources in one traceable flow. |
| Big Data Pipeline Architecture | Manage massive lease, listing, and asset datasets with versioning, schema control, and audit-ready flow. |
| Web Scraping Shopify | Monitor real estate service storefronts (e.g., proptech data extraction tools, short-term rentals) for pricing and offers. |
| Data Scraping Magento | Track inventory and pricing changes on property-related eCommerce setups using Magento engines. |
| Shopee Data Scraping | Useful for agents tracking low-tier rental inventory or furnishings resold on Shopee-like marketplaces. |
| Web Scraping Flight Data | Use flight arrivals and delays to optimize commercial real estate near airports or transit hubs. |
| How To Scrape booking.com | Scrape Booking to monitor local hotel demand, pricing elasticity, and short-term rental competition. |
| Competitive Analysis and Benchmarking | Track local developers and CRE competitors’ pricing, inventory, and market positioning in real time. |
| eCommerce Data Scraping | Extract product-level data tied to furnishing, lighting, and home equipment in rental developments. |
| Big Data Analytics in Retail Industry | Analyze tenant retail performance to inform lease terms, rent escalations, or anchor risk scenarios. |
| How to Scrape Data from Naver | Useful in Asia-based CRE projects, tracking tenant presence, user reviews, or local zoning news. |
| Hotel Data Scraping | Extract real-time hotel listings, occupancy, and rates for underwriting hospitality assets. |
| How to Scrape Data from Google Maps | Scrape locations, hours, reviews, and nearby POIs to model walkability, traffic, and zoning context. |
| Rotating Proxy for Scraping | Enable stable, compliant multi-site scraping across CRE portals, registries, and agency sites. |
| Social Media Scraping | Track tenant brand sentiment, foot traffic trends, or competitor launches from public social data. |
Want pipelines, not scripts?
We’ll scope, build, and deploy your CRE data extraction infrastructure—with audit logs, OCR parsing, and multi-source sync.
FAQ
-
How to extract data from real estate website legally?
To stay compliant, teams must respect the platform’s terms of service, avoid scraping gated content, and follow regional privacy rules like GDPR and CCPA. Technical safeguards include geofencing, robots.txt detection, and legal reviews of automated collection logic. At GroupBWT, we enforce compliance by design—embedding audit logging, fallback flows, and jurisdictional filters into every pipeline.
-
What kind of software handles unstructured lease documents?
The most reliable tools for scanned leases integrate OCR, clause-level segmentation, and NLP-based risk detection. These systems transform unsearchable PDFs into structured records, feeding lease terms, payment schedules, and exclusivity triggers into downstream tools automatically. GroupBWT’s pipeline extracts, validates, and exports structured metadata from tens of thousands of lease files monthly.
-
Why is automation still limited at many real estate companies?
Many teams still operate with disjointed tools—manual uploads, legacy databases, and static reporting. Automation breaks down when internal systems lack clean integration layers. Most real estate firms don’t have a centralized ingestion layer to unify structured and unstructured inputs across platforms. That’s exactly what we build: modular, audit-ready ingestion infrastructure that connects listings, leases, sensors, and registry data, without human bottlenecks. Real automation requires treating data capture as infrastructure, not a set of isolated scripts.
-
How do browser-based collectors differ from platform APIs?
Browser-based collectors simulate user behavior to fetch visible data from listing portals, documents, or records, even when APIs are unavailable or restricted. APIs, in contrast, provide structured feeds—but are often incomplete, outdated, or paywalled. The most resilient pipelines use both browser automation for depth, APIs for structure, and validation layers to unify results.
-
Why are clean data pipelines critical for underwriting systems?
Underwriting engines rely on inputs like lease terms, market comps, asset condition, and tenant risk. If this data is delayed, inconsistent, or incomplete, valuation errors and compliance gaps emerge. Structured, automated intake pipelines reduce latency, support audit-readiness, and accelerate investor decision-making, transforming how teams assess property risk and opportunity.




