

Every enterprise runs on decisions, but decisions run on the aggregated data.
When your sources are fragmented, timestamps misaligned, and formats inconsistent, insight collapses. The aggregate of data isn’t a byproduct—it’s the foundation. Without it, reporting breaks, models drift, and compliance fails.
According to the 2025 Market Research Future report , the global big data analytics market will grow from $77.1 billion in 2025 to $200 billion by 2035, driven by real-time pipelines, AI-integrated analytics, and cloud-first infrastructure.
For enterprise leaders managing fragmented data ecosystems, the priority is no longer data access, but actionable aggregation of data across internal, scraped, and third-party sources. With over 175 zettabytes of data projected globally by 2025, the only viable strategy is to design systems that can aggregate data across inputs, reduce latency, and deliver schema-aligned intelligence at scale.
Real-time readiness, integration flexibility, and multi-source aggregation aren’t bonuses—they are baseline. This shift explains why 43% of organizations cite real-time aggregated data as a top investment priority, and why companies using ML-based aggregation tools report 30% higher productivity.
Data Aggregation Overview: Decision-Grade Structure, Not Storage
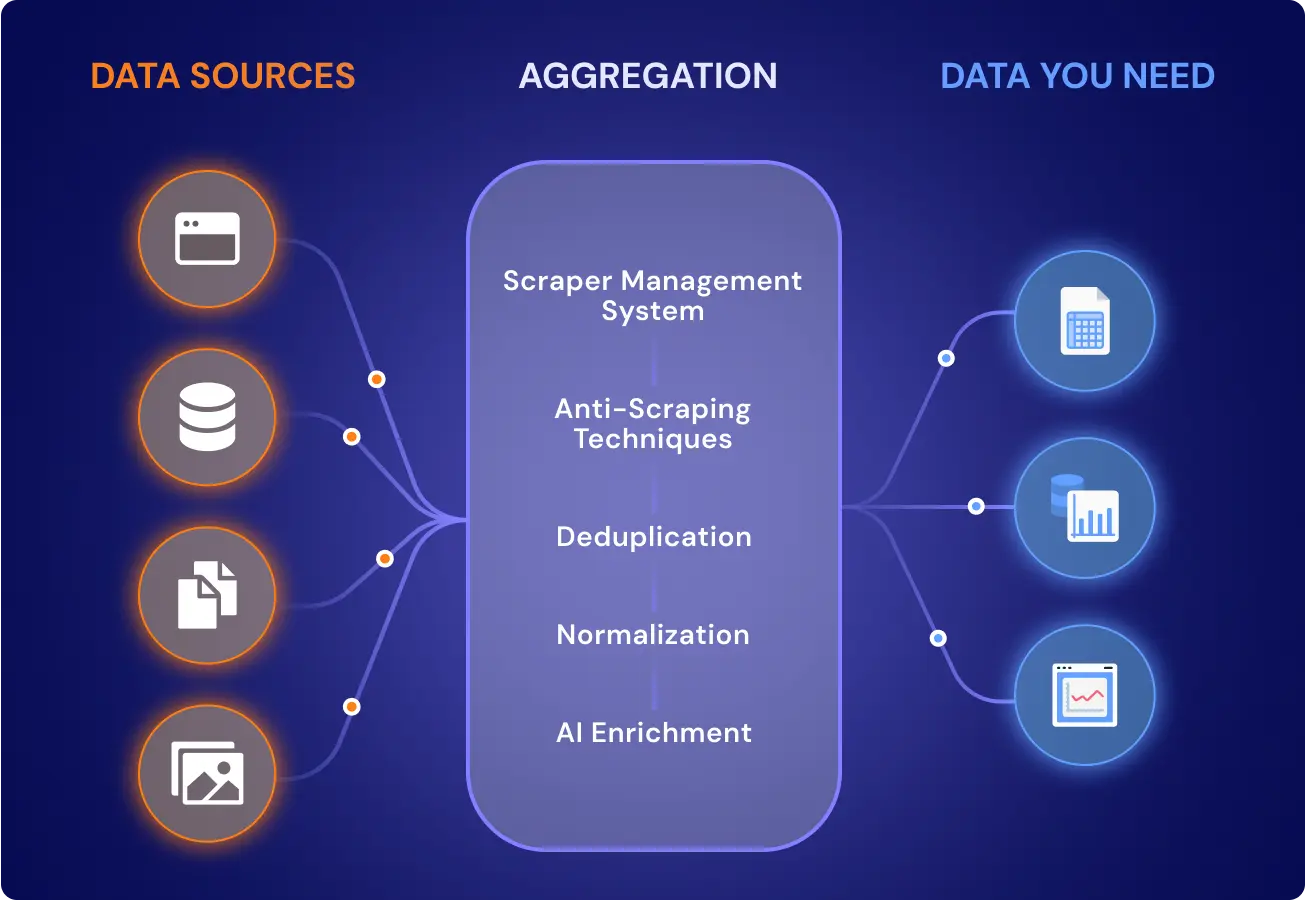
Data aggregation is the operational step that converts disjointed records into clean, structured units optimized for downstream decision-making—across dashboards, machine learning pipelines, and audit workflows. At enterprise scale, relying on expert big data development services is often necessary because the real work is rarely “collecting data”; it is enforcing the rules that make mixed sources behave like one system.
The contrarian point: aggregation is not a “merge” and it is not a “summary.” Data aggregation is schema-bound: it integrates data by matching field-level logic, not file location, because this is what produces model-grade readiness. That logic has to cover timestamp authority, field normalization, and source hierarchy—otherwise you get fast outputs that teams cannot trust.
“We tell clients that aggregation is about arbitration. When three sources disagree on a price, a timestamp, or a SKU, your aggregation logic is the judge. If you haven’t codified the laws of that courtroom—your ‘Source of Authority’ rules—you aren’t aggregating data; you’re just automating confusion.”
— Eugene Yushenko, CEO, GroupBWT
Aggregated data definition: Output datasets created by aligning fields like timestamps, categories, and source priority into a unified schema. Unlike summaries, these datasets retain traceability and logic, enabling downstream use in scoring systems, performance calculations, and audit pipelines.
The GroupBWT STAMP Contract (what aggregation must lock in)
- S — Schema rules: canonical field names, types, and keys
- T — Timestamp authority: which clock wins, how late data is handled
- A — Alignment & normalization: formats, categories, units, locales
- M — Merge precedence: deduplication + overwrite hierarchy by source priority
- P — Provenance: lineage links for every record (audit-ready traceability)
From the field: when STAMP is enforced, aggregation becomes an execution layer. In multi-market SKU monitoring, this approach reduced cross-vendor promo conflicts by 87% and achieved a 99.2% match rate across SKUs.
Aggregation Readiness Checklist
- What is the target schema the business will use as the “single version”?
- What is the trust boundary (ground truth vs overwrite rules)?
- What counts as a duplicate (ID, timestamp window, composite keys)?
- What is the latency budget (batch vs real-time, and why)?
- What are the audit requirements (lineage depth, retention, variance logs)?
Why Aggregate Data Matters
Aggregate data acts as the intelligence layer between data acquisition and decision execution. It introduces hierarchy, structure, and timing—three variables most raw systems ignore.
Without aggregation, data remains local, incompatible, and siloed. What does this mean in operational terms: duplicated reporting logic, increased reconciliation costs, and zero confidence in inter-system comparisons.
What does aggregate data mean for enterprises? It means the ability to detect system-wide anomalies, calculate cross-regional performance metrics, and ensure traceable governance across source systems.
Here’s how aggregate data alters functional workflows:
- Finance: Eliminates conflicting revenue views across billing systems
- Supply Chain: Resolves source-to-sink delivery mismatches
- Marketing: Aligns multichannel attribution windows without overlap
Aggregated data meaning refers not just to the result but to the shift in reliability. Aggregated records are not summaries—they are structured reflections of your operational reality, fit for audit, analysis, and automation.
Failing to aggregate doesn’t just affect reports. It corrupts pricing models, skews customer scoring, and introduces unrecoverable bias into AI inference layers. Aggregation is not about size. It’s about interpretability.
How Data Aggregation Works
Aggregating data follows a deterministic sequence of logic gates:
- Ingest: Pull data from APIs, files, crawlers, or DB snapshots
- Normalize: Align timestamp formats, categories, and field names
- Deduplicate: Remove redundancy using ID or timestamp logic
- Group: Apply key-based or time-based grouping logic
- Aggregate: Compute summary stats, attach source lineage
- Validate: Enforce schema, check consistency, log variances
At the core of this flow sits schema logic. Aggregation fails not at fetch, but at misalignment. Systems that don’t enforce field naming conventions, key uniqueness, or source priority cannot reliably aggregate data.
“The hardest part of aggregation isn’t volume; it’s entropy. Web sources change their schemas without warning. We engineer ‘schema drift’ detectors into the ingestion layer so that when a source changes a column name, the pipeline doesn’t break silently—it pauses, alerts, and waits for a human or automated fix before polluting your downstream model.”
— Alex Yudin, Head of Data Engineering, GroupBWT
How does data aggregation work at enterprise scale? It depends on the trust boundary. Aggregation workflows must include error logging, delayed ingestion handling, and schema versioning. Without these, summary logic becomes a failure.
How do you aggregate data across formats (CSV, JSON, SQL dumps)? You define a normalization contract—field mapping + date hierarchy + source precedence. You enforce it before the merge. You don’t guess.
Aggregation should not be treated as a mathematical function—it must follow enforceable logic structures, schema alignment rules, and traceability agreements.
Batch vs Real-Time Aggregation
Aggregation of data isn’t defined by speed—it’s defined by purpose. But the choice between batch and real-time aggregation determines whether your output serves forecasting, automation, or regulatory alignment.

Batch Aggregation
Batch processing aggregates large data inputs at set intervals—hourly, nightly, or monthly—to support audit logs, ERP reconciliation, or BI trendlines. It’s designed for systems where real-time isn’t required, but data accuracy and completeness must remain guaranteed.
Best used when:
- Ingesting third-party files (CSV, XML, JSON dumps)
- Aligning ledgers across ERP and CRM platforms
- Generating historical trendlines for BI dashboards
Definition of aggregate data in batch context: structured outputs aligned by time window, often used in actuarial reports, fiscal audits, or compliance logging.
Real-Time Aggregation
Real-time pipelines maintain continuously updated aggregate layers. Unlike batch jobs, they trigger on data change events, ingesting, grouping, and rewriting the aggregate of data in seconds.
Ideal when:
- Triggering pricing changes based on competitor signals
- Streaming telemetry from IoT fleets into ops dashboards
- Detecting anomalies in live financial or behavioral systems
What does it mean to aggregate data in real time? It means aggregation becomes part of the decision layer, not the reporting layer. Errors can’t hide. Systems must be schema-enforced, latency-aware, and rollback-capable.
“Real-time aggregation is seductive, but expensive. I advise clients to define their ‘latency budget’ first. Do you need sub-second updates for a dashboard that humans only check daily? We build systems that match the aggregation speed to the decision speed, saving infrastructure costs without sacrificing operational value”
— Oleg Boyko, COO, GroupBWT
Enterprises often combine both modes—batch for auditability, real-time for responsiveness.
Benefits and Limits of Aggregation
Data aggregation delivers structured outcomes if designed with schema logic and fault tolerance. The goal isn’t just to merge data. It’s to produce aligned, validated outputs that stand up to automation, audit, and real-time execution.
Structured Outcomes
Structured datasets are created by grouping and normalizing multiple entries based on shared characteristics such as time, source, or type. They are trusted, schema-bound layers built for calculation, scoring, and inference.
When executed correctly, aggregation of data produces:
- Reliability across systems: Conflicting records are resolved by priority logic and timestamp authority.
- Audit traceability: Every row links back to its origin, reducing the time and cost of reconciliation.
- Operational clarity: Distributed teams can work off a single version of performance metrics, reducing lag, overlap, and duplication.
To achieve this level of cross-system consistency, robust enterprise data integration and management strategies are paramount.
Real-world aggregation tasks—like financial consolidations, product catalog matching, or patient record integration—demand not speed, but reliability.
Each aggregate of data becomes a contract between business rules, technical integrity, and downstream system expectations. These outputs become the base layer for risk engines, BI dashboards, and regulatory reports.
Engineering Friction
While the aggregation enables consistency, it also introduces system-level complexity:
- Schema drift breaks the grouping logic unless versioned and enforced.
- Latency mismatches between sources introduce stale joins or reorder bias.
- Data gaps propagate unless explicitly logged and handled with fallback conditions.
- Source lineage becomes non-trivial, especially in multi-source merges or partner feeds.
What does it mean to aggregate data under production load? It means building not just ETL, but contracts. Aggregation pipelines must log, retry, checkpoint, and enforce. Otherwise, your insights remain unstable.
Even real-time aggregation has thresholds. It’s not just about stream ingestion—it’s about structured replay, rollback logic, and out-of-order handling. Without this, outputs may appear fresh but are corrupted.
GroupBWT Cases: Data Aggregation in Practice
GroupBWT builds aggregation pipelines where general-purpose data fails. The following anonymized cases illustrate how we solved real structural, compliance, and operational problems across key sectors. Each solution was schema-enforced, audit-ready, and built under NDA.
Align Flash Promos 5 Days Faster in OTA (Travel) Scraping
Problem: A global travel aggregator struggling to align booking windows and flash promotions across 40+ regional platforms. Data feeds included inconsistent timestamps, misaligned offers, and vendor-specific overrides.
Solution: We deployed a time-normalized aggregation system that aligned booking events, applied zone correction, and traced fare overrides to the source.
Results:
- Booking windows aligned across 40+ country-specific feeds
- Flash discount detection improved by 3–5 days
- Cross-vendor promo conflicts reduced by 87%
Enforce MAP Pricing in eCommerce & Retail in Under 6 Hours
Problem: A pricing intelligence team needed real-time SKU-level visibility to enforce MAP policies across multiple marketplaces. Off-the-shelf feeds lagged or lacked seller-level attribution.
Solution: We aggregated and reconciled 5,000+ live listings per cycle, standardizing price fields, region logic, and seller identity.
Results:
- 99.2% match rate across multi-market SKUs
- Hourly price deltas delivered with no post-correction needed
- Compliance trigger time reduced from 72 to 6 hours
Standardize 1M+ Listings in Automotive for Financing Accuracy
Problem: An automotive lender required unified vehicle data—including VINs, trim levels, and status—across fragmented dealer inventories in 60+ regions.
Solution: GroupBWT aggregated live feeds from APIs and portals, enforced trim-level schema rules, and verified status via title flags.
Results:
- 1M+ listings aggregated and enriched with ownership metadata
- 94% verified with geotag and trim-level accuracy
- Aggregated feeds enabled direct integration into financing workflows
Normalize Trial & Label Data Across 4 Jurisdictions in Healthcare
Problem: A healthcare platform needed to aggregate clinical trial data and product labels across languages and jurisdictions for AI model training.
Solution: We built a multilingual extraction pipeline with schema-bound mappings for trial endpoints, label categories, and approval stages.
Results:
- 25,000+ records normalized across four regulatory geographies
- Disambiguated trial phases, dosage, and submission fields
- Reduced manual annotation effort by over 60%
Segment Policy Clauses with 98% Accuracy in Insurance
Problem: An insurance required clause-level breakdowns of policy documents to feed a GPT-based claims advisory engine. Legal text lacks structural uniformity.
Solution: We parsed regional policy files into logic-aligned units, tagging clauses by type, payout conditions, and regional applicability.
Results:
- 98% clause segmentation accuracy across diverse document sets
- Enabled model alignment with policy options in five compliance zones
- Reduced manual clause validation to <5% of files
Deliver Earnings Data 30 Minutes Post-Call in Banking & Finance
Problem: A financial intelligence vendor needed real-time structuring of earnings call transcripts, including sentiment, EPS tracking, and forecast shifts.
Solution: We aggregated speech-to-text transcripts with labeled metadata, timestamp alignment, and company-specific normalization rules.
Results:
- Structured earnings data delivered within 30 minutes of call end
- Forecast accuracy improved by correlating sentiment with EPS deltas
- Model-ready outputs are integrated directly into investor dashboards
GroupBWT builds systems where raw data becomes actionable: aggregated, validated, and ready for AI, dashboards, audits, or ops. Below are aggregated insights from our real deployments.
Beyond the Core: Strategic Aggregation in Other Sectors
While the industries above show our deepest deployment history, aggregation delivers critical value across many more. The table below outlines where GroupBWT’s data engineering and aggregation expertise applies—and what leaders in those verticals can expect to gain.
| Industry | Aggregation Use Case | Problem Solved | Strategic Outcome |
| CyberSecurity | Threat feed consolidation across tools | No unified incident visibility | +67% correlation speed, -35% false positives |
| Legal Firms | Contract clause aggregation by jurisdiction | Manual clause lookup, version mismatch | -60% drafting time, +22% resolution accuracy |
| Beauty and Personal Care | Cross-brand SKU alignment by region | Ingredient duplication, SKU inflation | 93% reduction in duplicate listings |
| Patient Data Aggregation (Healthcare) | Record stitching from multiple care systems | Duplicate records, timestamp errors | 82% de-duplication, doubled analytics speed |
| Pharmaceutical Aggregation (Pharma) | Global trial and label field alignment | Regulatory mismatch, trial ambiguity | 98.7% field compliance, +58% AI training precision |
| Investment Aggregation (Banking & Finance) | Portfolio metadata harmonization | Risk scoring errors across asset classes | +21% accuracy in exposure forecasts |
| Retail Data Aggregation | Seller-wise pricing and inventory sync | Marketplace rule violations, stock-outs | -72% policy violations, real-time pricing insight |
| Telecom Aggregation | Plan availability and region logic mapping | Customer churn from mismatched info | 88% reduction in mismatch complaints |
| Logistics Aggregation | Delivery status unification across vendors | Shipment delays, data lag | +18% route accuracy, 40% fewer delivery disputes |
| Real Estate Aggregation | Field-agnostic listing normalization | No shared schema across portals | 3× match accuracy, 60% fewer manual tags |
Whether you’re a CTO fixing duplicate logic, a product lead cleaning listing feeds, or a compliance head preparing for audits, aggregation is your control layer. GroupBWT builds this layer to match your schema, update cycle, and trust threshold. For complex data sources like the ones outlined, we recommend partnering with a specialized aggregate content service provider .
How to Aggregate Data
Data aggregation isn’t a switch. It’s a structured operation. Whether you’re consolidating listings across 1,000 vendors or reconciling policy clauses from global subsidiaries, the process must follow schema-aligned logic and real-time reliability rules.
Below is a step-by-step breakdown of how organizations start, how GroupBWT delivers , and what operational models work best —from audit-grade batches to continuous, AI-ready pipelines.

Define What You Need Before You Aggregate
Aggregation begins long before the first byte is processed. Clients must clarify:
- Data sources: URLs, APIs, files, databases, or partner feeds
- Schema logic: Field names, timestamp formats, ID conventions
- Update frequency: Real-time, daily batch, weekly sync?
- Trust boundary: What’s accepted as ground truth? What gets overwritten?
Without these, aggregation introduces bias instead of structure.
What GroupBWT Handles End-to-End
As a partner, we handle all layers that turn your raw sources into structured, queryable intelligence.
Schema Mapping
We define and enforce schema logic, including what fields must exist, how they align, and which naming standards apply.
Deduplication Rules
We implement logic for record-level reconciliation by ID, timestamp, VIN, SKU, and other key fields, with a fallback hierarchy in place if any keys are missing.
Validation Layer
We include variance checks, null audits, and timestamp verification to ensure every record is trusted before ingestion. This crucial validation step often includes specialized methods found in web scraping using ChatGPT workflows for complex data cleaning.
Integration Hooks
We deliver outputs in whatever format your systems require: API, CSV, S3, SQL, Looker, or a streaming queue.
Logging & Traceability
All pipelines include observability: source tagging, retry logic, schema drift alerts, and field-level audit logs.
How We Build Aggregation Systems for Clients
Every deployment follows a structured four-phase process. We don’t just build scrapers—we build aggregation layers that last.
Phase 1: Discovery
We analyze:
- What types of data do you want aggregated
- Whether data exists internally, externally, or both
- What the expected output must look like (schema, latency, enrichment)
We also flag early risks: geo-differences, compliance flags, or schema instability.
Phase 2: Design
We create:
- Schema definitions
- Field-level mapping rules
- Deduplication and grouping logic
- Source hierarchy models (primary/secondary/fallback)
This design is reviewed and signed off on before the build begins.
Phase 3: Build & Deploy
We implement:
- Crawlers, scrapers, API calls, or connectors
- Aggregation logic
- Error handling and retry policies
- Logging and monitoring dashboards
We deliver the pipeline, test it end-to-end, and align it with your BI/AI stack. For reliable data flow, we implement core fundamental components detailed in ETL and data warehousing concepts .
Phase 4: Operate, Monitor, and Adapt
We maintain:
- Schema versioning
- Change monitoring for upstream sources
- Scaling plans if data volume or complexity increases
- Compliance adjustments for regulation changes (GDPR, HIPAA, CCPA, etc.)
Once deployed, every aggregation system enters a continuous lifecycle of operation and adaptation. GroupBWT ensures long-term system resilience, compliance, and business alignment. This full lifecycle management is why many organizations prefer a seamless web scraping as a service model over fragmented internal tools.
Delivery Models That Match Your Use Case
GroupBWT supports multiple deployment types based on business need, speed, and sensitivity.
One-Time Aggregation
Used for:
- Audit prep
- Historical normalization
- One-off compliance reports
Delivery: Single file or DB export with schema doc and lineage logs.
Scheduled Aggregation
Used for:
- Product feed refresh
- BI dashboard updates
- Pricing syncs
Delivery: Daily/weekly batches via API, cloud, or webhook.
Real-Time Aggregation
Used for:
- Fraud detection
- Dynamic pricing
- Behavioral signal pipelines
Delivery: Event-driven streams (Kafka, Redis, WebSockets) with <5s lag.
What You Need—And What You Don’t
You don’t need a full internal data lake or data science team. But you do need to know your target schema and systems. We handle the rest.
| What You Provide | What We Handle |
| Source access (or list) | Crawlers, connectors, and extraction |
| Target schema (or sketch) | Schema logic and mapping enforcement |
| Frequency expectations | Pipeline building and scheduling |
| Output format preferences | Delivery + integration + observability |
Governance, Privacy, and Compliance Built In
Aggregation isn’t just technical—it’s legal and operational too. GroupBWT delivers pipelines that are:
- Audit-traceable: Every record links to its source, timestamp, and transformation
- Privacy-compliant: Fields tagged for GDPR, HIPAA, or SOC2 compliance by design
- Error-resistant: Schema drift alerts, retry logic, rollback capability
- Vendor-agnostic: Data from scraped sources, internal tools, or third-party APIs can be mixed and normalized safely
We treat each aggregate of data as a regulated unit, built to comply with audit, privacy, and change-tracking standards. For highly fragmented data sources that require structural standardization, we offer specialized outsource data mining services to expose hidden patterns.
Start Your Aggregation Project with GroupBWT
Whether you’re consolidating listings, reconciling clauses, or building real-time pricing pipelines, GroupBWT can design and deliver your full aggregation system—schema-aligned, audit-ready, and integration-friendly. The crucial step of converting raw inputs into structured formats is increasingly handled by sophisticated AI data scraping tools to maintain velocity and accuracy.
[Request a Free 30-Min Consultation]
FAQ
-
What is the definition of aggregate data?
Aggregate data definition: structured output created by aligning fields like time, category, and source into one usable format. It’s not a summary. It’s the base layer for decisions, metrics, and automation.
-
What is the difference between the integration and aggregation of data?
Aggregate data organizes and unifies information based on logic, not location. Integration connects systems. Aggregation enforces structure for reliable use in models, dashboards, or reports.
-
How does data aggregation work?
It starts with pulling raw records, then aligning them by schema, removing duplicates, and grouping by key fields like timestamp or category. Aggregating data turns messy inputs into trusted, reusable outputs.
-
What makes aggregation different from data cleaning or enrichment?
Aggregation isn’t cleanup or decoration—it’s structure.
- Data cleaning removes errors (eg, nulls, duplicates, typos).
- Enrichment adds context (eg, appending geodata or labels).
- Aggregation enforces logic—grouping, timestamp alignment, and schema structure to make records usable across systems.
Aggregation is what transforms raw inputs into queryable, reliable, and decision-grade outputs . Without it, even clean or enriched data remains siloed and incompatible.
-
How do you aggregate data?
We define a schema, map each source to that structure, and apply validation rules to every row. That’s how to aggregate data without data loss or field mismatch.
-
Can you aggregate scraped + internal + third-party data?
Yes. Aggregating data from mixed sources works when the schema is clear and trust rules are defined. We normalize, stitch, and trace every record back to its origin.




